信息收集
利用搜索引擎作信息收集
https://owasp.org/www-project-web-security-testing-guide/latest/4-Web_Application_Security_Testing/01-Information_Gathering/01-Conduct_Search_Engine_Discovery_Reconnaissance_for_Information_Leakage
概括
为了让搜索引擎工作,计算机程序(或)定期从网络上的数十亿页面中robots获取数据(称为爬行)。这些程序通过跟踪其他页面的链接或查看站点地图来查找 Web 内容和功能。如果一个网站使用一个特殊的文件robots.txt来列出它不希望搜索引擎获取的页面,那么列出的页面将被忽略。这是一个基本概述 - Google 对搜索引擎的工作原理提供了更深入的解释。
测试人员可以使用搜索引擎对网站和 Web 应用程序执行侦察。搜索引擎发现和侦察有直接和间接的要素:直接方法涉及从缓存中搜索索引和相关内容,而间接方法涉及通过搜索论坛、新闻组和招标网站来学习敏感的设计和配置信息。
一旦搜索引擎机器人完成爬行,它就会开始根据标签和相关属性(例如 )对网页内容编制索引<TITLE>,以便返回相关的搜索结果。如果robots.txt文件在网站的生命周期内没有更新,并且没有使用指示机器人不索引内容的内联 HTML 元标记,那么索引可能包含网站不打算包含的内容拥有者。网站所有者可以使用前面提到robots.txt的 HTML 元标记、身份验证和搜索引擎提供的工具来删除此类内容。
测试目标
- 确定应用程序、系统或组织的哪些敏感设计和配置信息直接(在组织的网站上)或间接(通过第三方服务)公开。
如何测试
使用搜索引擎搜索可能敏感的信息。这可能包括:
- 网络图和配置;
- 管理员或其他主要员工的存档帖子和电子邮件;
- 登录程序和用户名格式;
- 用户名、密码和私钥;
- 第三方或云服务配置文件;
- 显示错误信息内容;和
- 非公共应用程序(开发、测试、用户验收测试 (UAT) 和站点的暂存版本)。
搜索引擎
不要将测试仅限于一个搜索引擎提供商,因为不同的搜索引擎可能会产生不同的结果。搜索引擎结果可能会在几个方面有所不同,具体取决于引擎上次抓取内容的时间,以及引擎用来确定相关页面的算法。考虑使用以下(按字母顺序列出的)搜索引擎:
- 百度,中国最受欢迎的搜索引擎。
- Bing是微软拥有和运营的搜索引擎,全球第二受欢迎。支持高级搜索关键字。
- binsearch.info,二进制 Usenet 新闻组的搜索引擎。
- Common Crawl,“任何人都可以访问和分析的网络爬虫数据的开放存储库。”
- DuckDuckGo是一个以隐私为中心的搜索引擎,可以从许多不同的来源编译结果。支持搜索语法。
- Google提供世界上最受欢迎的搜索引擎,并使用排名系统尝试返回最相关的结果。支持搜索运算符。
- Internet Archive Wayback Machine,“以数字形式构建互联网站点和其他文化制品的数字图书馆。”
- Shodan,一种用于搜索联网设备和服务的服务。使用选项包括有限的免费计划以及付费订阅计划。
搜索运算符
搜索运算符是一种特殊的关键字或语法,可扩展常规搜索查询的功能,并有助于获得更具体的结果。它们通常采用operator:query. 以下是一些通常支持的搜索运算符:
site:将搜索限制在提供的域中。inurl:将只返回在 URL 中包含关键字的结果。intitle:只会返回页面标题中包含关键字的结果。intext:或者inbody:只会在页面正文中搜索关键字。filetype:将仅匹配特定文件类型,即.png, 或.php.
例如,要查找由典型搜索引擎索引的 owasp.org 的 Web 内容,所需语法为:
site:owasp.org
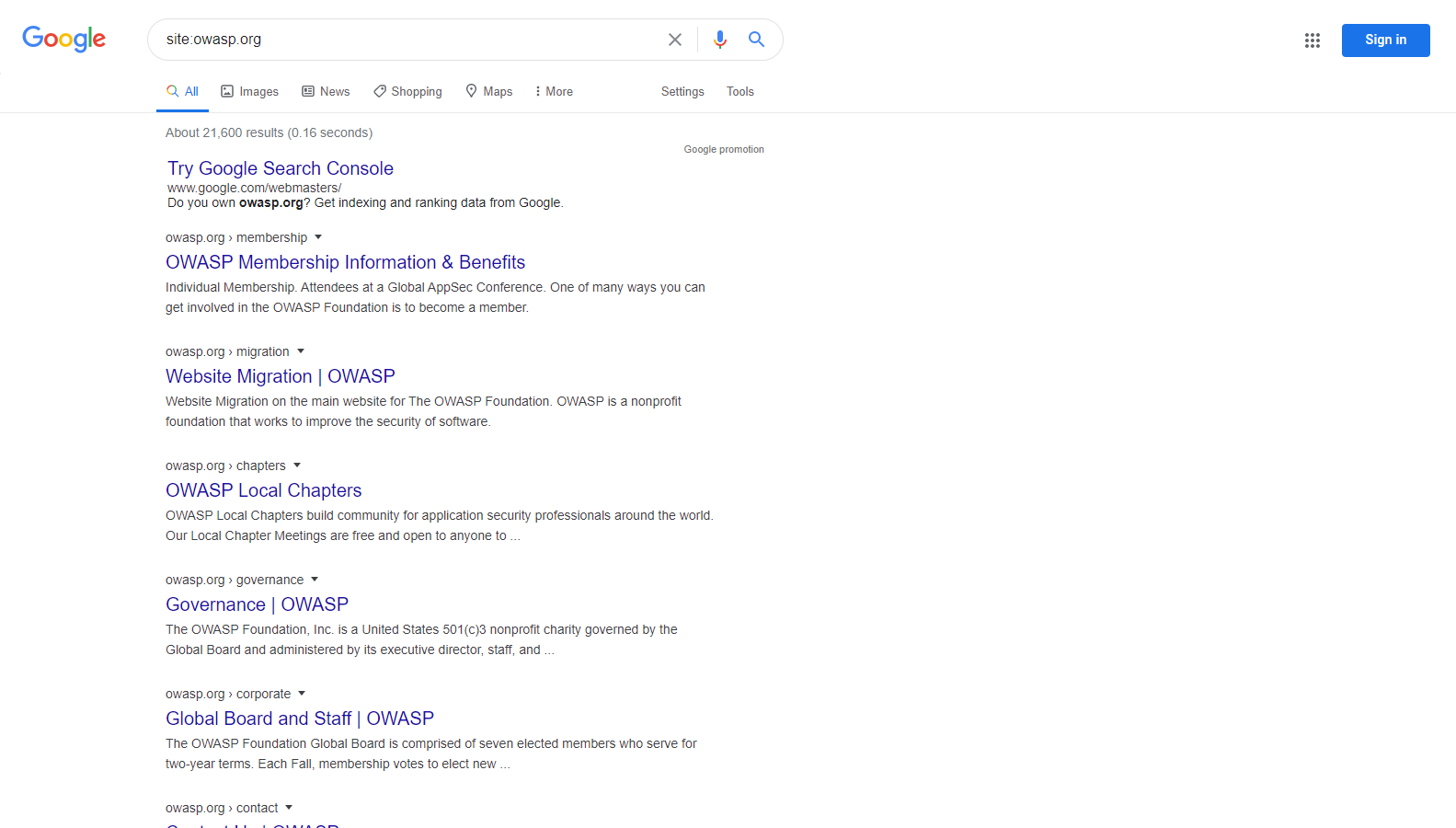
图 4.1.1-1:Google 站点操作搜索结果示例
查看缓存内容
要搜索以前已编入索引的内容,请使用cache:运算符。这有助于查看自索引以来可能已更改的内容,或者可能不再可用的内容。并非所有搜索引擎都提供缓存内容进行搜索;在撰写本文时最有用的来源是谷歌。
要owasp.org在缓存时查看,语法为:
cache:owasp.org
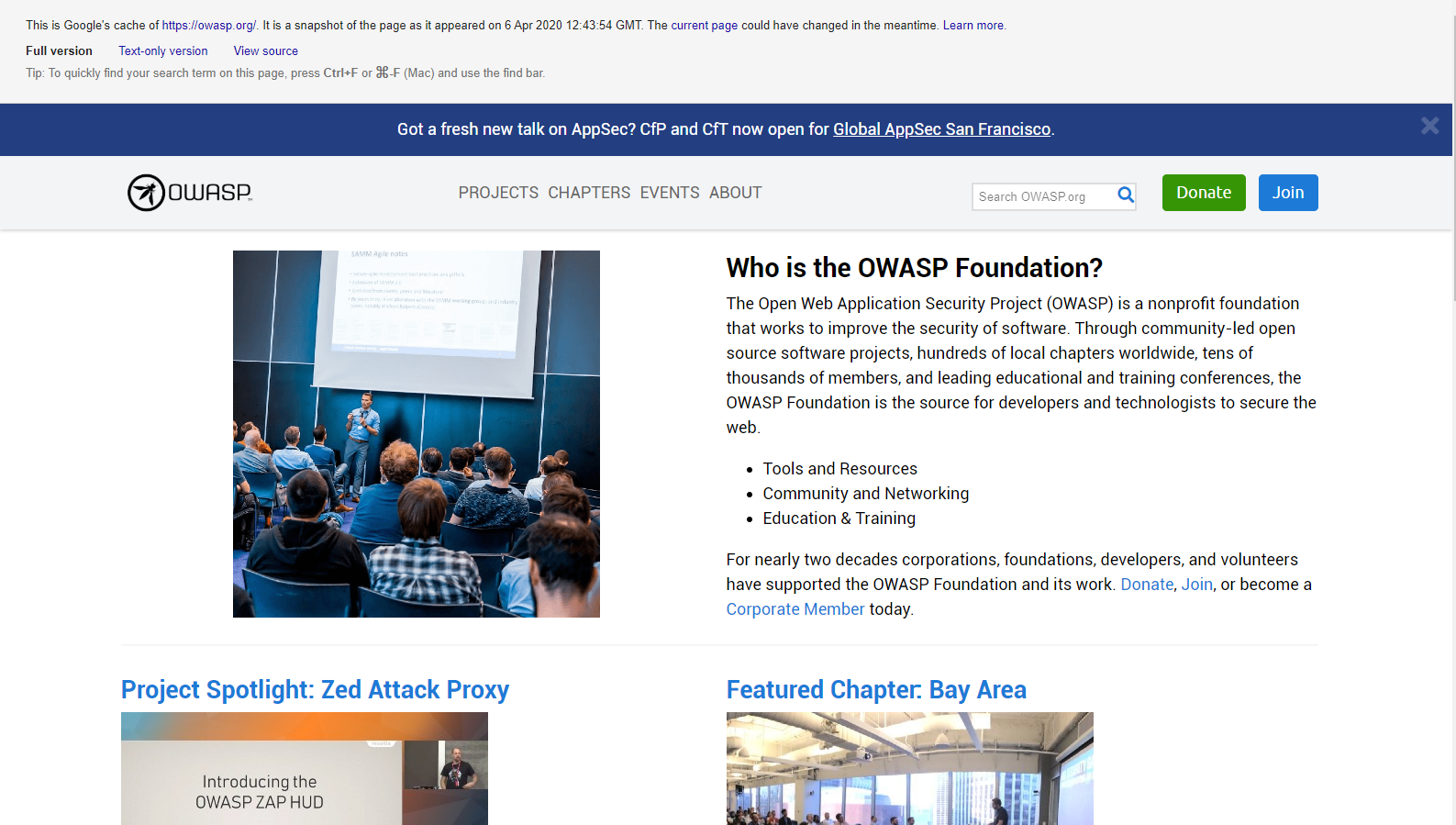
图 4.1.1-2:谷歌缓存操作搜索结果示例
谷歌黑客,或 Dorking
当与测试人员的创造力相结合时,使用运算符进行搜索可能是一种非常有效的发现技术。可以链接运算符以有效地发现特定种类的敏感文件和信息。这种称为Google hacking或 Dorking 的技术也可以使用其他搜索引擎,只要支持搜索运算符。
诸如Google Hacking Database之类的 dorks 数据库是一种有用的资源,可以帮助发现特定信息。该数据库中可用的一些类别的 dorks 包括:
- 立足点
- 包含用户名的文件
- 敏感目录
- Web 服务器检测
- 易受攻击的文件
- 易受攻击的服务器
- 错误信息
- 包含多汁信息的文件
- 包含密码的文件
- 敏感的在线购物信息
整治
在将设计和配置信息发布到网上之前,请仔细考虑其敏感性。
定期审查在线发布的现有设计和配置信息的敏感性。 https://owasp.org/www-project-web-security-testing-guide/latest/4-Web_Application_Security_Testing/01-Information_Gathering/03-Review_Webserver_Metafiles_for_Information_Leakage
查看Web meta 文件有无敏感信息
概括
本节介绍如何测试各种元数据文件是否存在 Web 应用程序路径或功能的信息泄漏。此外,蜘蛛、机器人或爬虫要避免的目录列表也可以创建为通过应用程序映射执行路径的依赖项。还可以收集其他信息以识别攻击面、技术细节或用于社会工程参与。
测试目标
- 通过分析元数据文件识别隐藏或混淆的路径和功能。
- 提取并映射可能导致更好地了解手头系统的其他信息。
如何测试
下面用 执行的任何操作
wget也可以用 完成curl。许多动态应用程序安全测试 (DAST) 工具(例如 ZAP 和 Burp Suite)都包含对这些资源的检查或解析,作为其蜘蛛/爬虫功能的一部分。还可以使用各种Google Dorks或利用诸如inurl:.
机器人
Web Spiders、Robots 或 Crawlers 检索网页,然后递归遍历超链接以检索更多的 Web 内容。它们可接受的行为由Web 根目录中的robots.txt文件的机器人排除协议指定。
例如,下面引用了 2020 年 5 月 5 日从Googlerobots.txt采样的文件的开头:
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
Disallow: /sdch
...
User-Agent指令是指特定的网络蜘蛛/机器人/爬虫。例如,User-Agent: Googlebot指的是来自谷歌的蜘蛛,而User-Agent: bingbot指的是来自微软的爬虫。User-Agent: *在上面的例子中适用于所有网络蜘蛛/机器人/爬虫。
该Disallow指令指定哪些资源被蜘蛛/机器人/爬虫禁止。在上面的示例中,禁止以下内容:
...
Disallow: /search
...
Disallow: /sdch
...
网络蜘蛛/机器人/爬虫可以故意忽略Disallow文件中指定的指令robots.txt。因此,robots.txt不应将其视为对第三方访问、存储或重新发布 Web 内容的方式实施限制的机制。
该robots.txt文件是从 Web 服务器的 Web 根目录中检索的。例如,要使用or检索robots.txtfrom :www.google.com``wget``curl
$ curl -O -Ss http://www.google.com/robots.txt && head -n5 robots.txt
User-agent: *
Disallow: /search
Allow: /search/about
Allow: /search/static
Allow: /search/howsearchworks
...
使用 Google 网站站长工具分析 robots.txt
网站所有者可以使用 Google 的“Analyze robots.txt”功能来分析网站,作为其Google 网站管理员工具的一部分。该工具可以辅助测试,流程如下:
- 使用 Google 帐户登录 Google 网站站长工具。
- 在仪表板上,输入要分析的站点的 URL。
- 在可用方法之间进行选择,然后按照屏幕上的说明进行操作。
元标签
<META>标记位于HEAD每个 HTML 文档的部分内,并且在机器人/蜘蛛/爬虫起点不是从 webroot 以外的文档链接(即深层链接)开始的情况下,应该在整个网站上保持一致。Robots 指令也可以通过使用特定的META 标记来指定。
机器人 META 标签
如果没有<META NAME="ROBOTS" ... >条目,则“机器人排除协议”默认为INDEX,FOLLOW分别。因此,“机器人排除协议”定义的另外两个有效条目以NO...ieNOINDEX和为前缀NOFOLLOW。
根据 webroot 文件中列出的 Disallow 指令,在每个网页中进行robots.txt正则表达式搜索,并将结果与 webroot 中的文件进行比较。<META NAME="ROBOTS"``robots.txt
杂项元信息标签
组织经常在 Web 内容中嵌入信息 META 标签以支持各种技术,例如屏幕阅读器、社交网络预览、搜索引擎索引等。此类元信息对于测试人员识别所使用的技术以及要探索的其他路径/功能可能很有价值和测试。以下元信息是www.whitehouse.gov在 2020 年 5 月 5 日通过查看页面源检索到的:
...
<meta property="og:locale" content="en_US" />
<meta property="og:type" content="website" />
<meta property="og:title" content="The White House" />
<meta property="og:description" content="We, the citizens of America, are now joined in a great national effort to rebuild our country and to restore its promise for all. – President Donald Trump." />
<meta property="og:url" content="https://www.whitehouse.gov/" />
<meta property="og:site_name" content="The White House" />
<meta property="fb:app_id" content="1790466490985150" />
<meta property="og:image" content="https://www.whitehouse.gov/wp-content/uploads/2017/12/wh.gov-share-img_03-1024x538.png" />
<meta property="og:image:secure_url" content="https://www.whitehouse.gov/wp-content/uploads/2017/12/wh.gov-share-img_03-1024x538.png" />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:description" content="We, the citizens of America, are now joined in a great national effort to rebuild our country and to restore its promise for all. – President Donald Trump." />
<meta name="twitter:title" content="The White House" />
<meta name="twitter:site" content="@whitehouse" />
<meta name="twitter:image" content="https://www.whitehouse.gov/wp-content/uploads/2017/12/wh.gov-share-img_03-1024x538.png" />
<meta name="twitter:creator" content="@whitehouse" />
...
<meta name="apple-mobile-web-app-title" content="The White House">
<meta name="application-name" content="The White House">
<meta name="msapplication-TileColor" content="#0c2644">
<meta name="theme-color" content="#f5f5f5">
...
站点地图
站点地图是一个文件,开发人员或组织可以在其中提供有关站点或应用程序提供的页面、视频和其他文件的信息,以及它们之间的关系。搜索引擎可以使用此文件更智能地探索您的网站。测试人员可以使用sitemap.xml文件来了解有关站点或应用程序的更多信息,从而更全面地探索它。
以下摘录自 2020 年 5 月 5 日检索到的 Google 主要站点地图。
$ wget --no-verbose https://www.google.com/sitemap.xml && head -n8 sitemap.xml
2020-05-05 12:23:30 URL:https://www.google.com/sitemap.xml [2049] -> "sitemap.xml" [1]
<?xml version="1.0" encoding="UTF-8"?>
<sitemapindex xmlns="http://www.google.com/schemas/sitemap/0.84">
<sitemap>
<loc>https://www.google.com/gmail/sitemap.xml</loc>
</sitemap>
<sitemap>
<loc>https://www.google.com/forms/sitemaps.xml</loc>
</sitemap>
...
测试人员可能希望从那里探索以检索 gmail 站点地图https://www.google.com/gmail/sitemap.xml:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" xmlns:xhtml="http://www.w3.org/1999/xhtml">
<url>
<loc>https://www.google.com/intl/am/gmail/about/</loc>
<xhtml:link href="https://www.google.com/gmail/about/" hreflang="x-default" rel="alternate"/>
<xhtml:link href="https://www.google.com/intl/el/gmail/about/" hreflang="el" rel="alternate"/>
<xhtml:link href="https://www.google.com/intl/it/gmail/about/" hreflang="it" rel="alternate"/>
<xhtml:link href="https://www.google.com/intl/ar/gmail/about/" hreflang="ar" rel="alternate"/>
...
安全TXT
security.txt被 IETF 批准为RFC 9116 - 一种有助于安全漏洞披露的文件格式,允许网站定义安全策略和联系方式。有多种原因可能对测试场景感兴趣,包括但不限于:
- 识别进一步的路径或资源以包含在发现/分析中。
- 开源情报收集。
- 查找有关 Bug Bounties 等的信息。
- 社会工程学。
该文件可能存在于网络服务器的根目录中或.well-known/目录中。前任:
https://example.com/security.txthttps://example.com/.well-known/security.txt
这是从 LinkedIn 2020 年 5 月 5 日检索到的真实示例:
$ wget --no-verbose https://www.linkedin.com/.well-known/security.txt && cat security.txt
2020-05-07 12:56:51 URL:https://www.linkedin.com/.well-known/security.txt [333/333] -> "security.txt" [1]
# Conforms to IETF `draft-foudil-securitytxt-07`
Contact: mailto:security@linkedin.com
Contact: https://www.linkedin.com/help/linkedin/answer/62924
Encryption: https://www.linkedin.com/help/linkedin/answer/79676
Canonical: https://www.linkedin.com/.well-known/security.txt
Policy: https://www.linkedin.com/help/linkedin/answer/62924
人类 TXT
humans.txt是一个了解网站背后的人的倡议。它采用文本文件的形式,其中包含有关为构建网站做出贡献的不同人员的信息。该文件通常(但不总是)包含有关职业或工作地点/路径的信息。
以下示例检索自 Google 2020 年 5 月 5 日:
$ wget --no-verbose https://www.google.com/humans.txt && cat humans.txt
2020-05-07 12:57:52 URL:https://www.google.com/humans.txt [286/286] -> "humans.txt" [1]
Google is built by a large team of engineers, designers, researchers, robots, and others in many different sites across the globe. It is updated continuously, and built with more tools and technologies than we can shake a stick at. If you'd like to help us out, see careers.google.com.
其他众所周知的信息来源
还有其他 RFC 和 Internet 草案建议在.well-known/目录中对文件进行标准化使用。可以在此处或此处找到其中的列表。
测试人员查看 RFC/草稿并创建一个列表以提供给爬虫或模糊器,以验证此类文件的存在或内容,这将是相当简单的。
工具
- 浏览器(查看源代码或开发工具功能)
- 卷曲
- wget
- 打嗝套件
- ZAP
枚举 Web 服务器上的应用程序
https://owasp.org/www-project-web-security-testing-guide/latest/4-Web_Application_Security_Testing/01-Information_Gathering/04-Enumerate_Applications_on_Webserver
概括
测试 Web 应用程序漏洞的最重要步骤是找出 Web 服务器上托管了哪些特定应用程序。许多应用程序都有已知的漏洞和已知的攻击策略,可以利用这些漏洞和攻击策略来获得远程控制或利用数据。此外,许多应用程序经常配置错误或未更新,因为人们认为它们仅在“内部”使用,因此不存在威胁。随着虚拟 Web 服务器的激增,IP 地址和 Web 服务器之间传统的 1:1 关系正在失去其原有的大部分意义。多个网站或应用程序的符号名称解析为同一 IP 地址的情况并不少见。这种场景不仅限于托管环境,也适用于普通的企业环境。
安全专业人员有时会获得一组 IP 地址作为测试目标。有争议的是,此场景更类似于渗透测试类型的参与,但无论如何,预计此类任务将测试可通过此目标访问的所有 Web 应用程序。问题是给定的 IP 地址在端口 80 上托管 HTTP 服务,但是如果测试人员应该通过指定 IP 地址(这是他们所知道的)访问它,它会报告“此地址未配置 Web 服务器”或类似消息. 但是该系统可以“隐藏”许多与不相关的符号 (DNS) 名称关联的 Web 应用程序。显然,分析的范围深受测试人员测试所有应用程序或只测试他们知道的应用程序的影响。
有时,目标规范更丰富。测试人员可能会得到一个 IP 地址列表及其相应的符号名称。然而,这个列表可能传达了部分信息,即它可能省略了一些符号名称,而客户甚至可能没有意识到这一点(这在大型组织中更有可能发生)。
影响评估范围的其他问题由在非明显 URL(例如,http://www.example.com/some-strange-URL)上发布的 Web 应用程序表示,这些 URL 未在其他地方引用。这可能是由于错误(由于配置错误)或有意(例如,未公布的管理界面)造成的。
为了解决这些问题,有必要执行 Web 应用程序发现。
测试目标
- 枚举范围内存在于 Web 服务器上的应用程序。
如何测试
Web 应用程序发现是一个旨在识别给定基础架构上的 Web 应用程序的过程。后者通常指定为一组 IP 地址(可能是一个网络块),但也可能包含一组 DNS 符号名称或两者的混合。这些信息在评估执行之前分发,无论是经典风格的渗透测试还是以应用程序为中心的评估。在这两种情况下,除非参与规则另有规定(例如,仅测试位于 URL 的应用程序http://www.example.com/),否则评估应力求范围最全面,即它应识别可通过给定目标访问的所有应用程序。以下示例检查了可用于实现此目标的一些技术。
以下一些技术适用于面向 Internet 的 Web 服务器,即 DNS 和反向 IP 基于 Web 的搜索服务以及搜索引擎的使用。示例使用私有 IP 地址(例如
192.168.1.100),除非另有说明,否则代表_通用_IP 地址并且仅用于匿名目的。
影响有多少应用程序与给定 DNS 名称(或 IP 地址)相关的三个因素:
-
不同的基本 URL
Web 应用程序的明显入口点是
www.example.com,即,使用这种简写符号,我们认为 Web 应用程序起源于http://www.example.com/(这同样适用于 HTTPS)。然而,即使这是最常见的情况,也没有强制应用程序从/.例如,相同的符号名称可能与三个 Web 应用程序相关联,例如:
http://www.example.com/url1http://www.example.com/url2http://www.example.com/url3在这种情况下,URL
http://www.example.com/不会与有意义的页面相关联,并且这三个应用程序将被隐藏,除非测试人员明确知道如何访问它们,即测试人员知道_url1_、url2_或_url3。通常不需要以这种方式发布 Web 应用程序,除非所有者不希望以标准方式访问它们,并且准备告知用户其确切位置。这并不意味着这些应用程序是秘密的,只是它们的存在和位置没有被明确公布。 -
非标准端口
虽然 Web 应用程序通常位于端口 80 (HTTP) 和 443 (HTTPS) 上,但这些端口号并没有什么神奇之处。事实上,Web 应用程序可能与任意 TCP 端口相关联,并且可以通过指定端口号来引用,如下所示:
http[s]://www.example.com:port/. 例如,http://www.example.com:20000/。 -
虚拟主机
DNS 允许单个 IP 地址与一个或多个符号名称相关联。例如,IP 地址
192.168.1.100可能与 DNS 名称www.example.com、helpdesk.example.com、相关联webmail.example.com。不必所有名称都属于同一个 DNS 域。这种 1 对 N 的关系可以反映为通过使用所谓的虚拟主机来提供不同的内容。我们所指的指定虚拟主机的信息嵌入在 HTTP 1.1主机标头中。人们不会怀疑除了显而易见的之外还有其他 Web 应用程序的存在
www.example.com,除非他们知道helpdesk.example.com和webmail.example.com。
解决问题 1 的方法 - 非标准 URL
没有办法完全确定是否存在非标准命名的 Web 应用程序。由于是非标准的,因此没有管理命名约定的固定标准,但是测试人员可以使用多种技术来获得一些额外的洞察力。
首先,如果 Web 服务器配置错误并允许目录浏览,则可能会发现这些应用程序。漏洞扫描器可能在这方面有所帮助。
其次,这些应用程序可能会被其他网页引用,并且有可能被网络搜索引擎抓取和索引。如果测试人员怀疑此类隐藏应用程序的存在,www.example.com他们可以使用_网站_运营商进行搜索并检查查询结果site: www.example.com。在返回的 URL 中,可能有一个指向这样一个不明显的应用程序。
另一种选择是探测可能是未发布应用程序候选者的 URL。例如,可以从 https://www.example.com/webmail、https://webmail.example.com/ 或 https://mail.example.com/等 URL 访问 Web邮件前端。这同样适用于管理界面,它们可以在隐藏的 URL 上发布(例如,Tomcat 管理界面),但不会在任何地方引用。因此,进行一些字典式搜索(或“智能猜测”)可能会产生一些结果。漏洞扫描器可能在这方面有所帮助。
解决问题 2 的方法 - 非标准端口
很容易检查非标准端口上是否存在 Web 应用程序。Nmap等端口扫描器可以通过-sV选项进行服务识别,识别任意端口上的http[s]服务。所需要的是对整个 64k TCP 端口地址空间的全面扫描。
例如,以下命令将通过 TCP 连接扫描查找 IP 上所有打开的端口,192.168.1.100并尝试确定哪些服务绑定到它们(仅显示_必要_的开关 - Nmap 具有广泛的选项集,其讨论是超出范围):
nmap –Pn –sT –sV –p0-65535 192.168.1.100
检查输出并查找 HTTP 或 TLS 包装服务的指示(应探测以确认它们是 HTTPS)就足够了。例如,上一个命令的输出可能如下所示:
Interesting ports on 192.168.1.100:
(The 65527 ports scanned but not shown below are in state: closed)
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 3.5p1 (protocol 1.99)
80/tcp open http Apache httpd 2.0.40 ((Red Hat Linux))
443/tcp open ssl OpenSSL
901/tcp open http Samba SWAT administration server
1241/tcp open ssl Nessus security scanner
3690/tcp open unknown
8000/tcp open http-alt?
8080/tcp open http Apache Tomcat/Coyote JSP engine 1.1
从这个例子中,可以看出:
- 有一个 Apache HTTP 服务器在端口 80 上运行。
- 443端口好像有HTTPS服务器(不过这个需要确认,比如
https://192.168.1.100用浏览器访问)。 - 在端口 901 上有一个 Samba SWAT Web 界面。
- 端口 1241 上的服务不是 HTTPS,而是 TLS 封装的 Nessus 守护进程。
- 端口 3690 具有未指定的服务(Nmap 返回其_指纹_- 此处为清楚起见省略 - 以及将其提交并纳入 Nmap 指纹数据库的说明,前提是您知道它代表的服务)。
- 端口 8000 上的另一个未指定服务;这可能是 HTTP,因为在此端口上找到 HTTP 服务器并不罕见。让我们检查一下这个问题:
$ telnet 192.168.10.100 8000
Trying 192.168.1.100...
Connected to 192.168.1.100.
Escape character is '^]'.
GET / HTTP/1.0
HTTP/1.0 200 OK
pragma: no-cache
Content-Type: text/html
Server: MX4J-HTTPD/1.0
expires: now
Cache-Control: no-cache
<html>
...
这证实它实际上是一个 HTTP 服务器。或者,测试人员可以使用网络浏览器访问该 URL;或使用 GET 或 HEAD Perl 命令,它们模仿 HTTP 交互,例如上面给出的交互(但是 HEAD 请求可能不会被所有服务器接受)。
- Apache Tomcat 在端口 8080 上运行。
漏洞扫描器可能会执行相同的任务,但首先检查所选扫描器是否能够识别在非标准端口上运行的 HTTP[S] 服务。例如,Nessus 能够在任意端口上识别它们(前提是它被指示扫描所有端口),并且将提供关于 Nmap 的大量针对已知 Web 服务器漏洞的测试,以及 TLS/ HTTPS 服务的 SSL 配置。如前所述,Nessus 还能够发现流行的应用程序或 web 界面,否则可能会被忽视(例如,Tomcat 管理界面)。
解决问题 3 的方法 - 虚拟主机
有许多技术可用于识别与给定 IP 地址关联的 DNS 名称x.y.z.t。
DNS 区域传输
考虑到 DNS 服务器基本上不支持区域传输这一事实,这种技术现在的使用受到限制。但是,这可能值得一试。首先,测试人员必须确定服务于x.y.z.t. 如果一个符号名称已知x.y.z.t(假设为),则可以通过、或等工具通过请求 DNS NS 记录www.example.com来确定其名称服务器。nslookup``host``dig
如果没有已知的符号名称x.y.z.t,但目标定义至少包含一个符号名称,测试人员可能会尝试应用相同的过程并查询该名称的名称服务器(希望该名称服务器x.y.z.t也能提供服务)。例如,如果目标由 IP 地址x.y.z.t和名称组成mail.example.com,则确定域的名称服务器example.com。
以下示例显示如何www.owasp.org使用以下host命令识别名称服务器:
$ host -t ns www.owasp.org
www.owasp.org is an alias for owasp.org.
owasp.org name server ns1.secure.net.
owasp.org name server ns2.secure.net.
现在可以向域的名称服务器请求区域传输example.com。如果测试人员幸运的话,他们将得到该域的 DNS 条目列表。这将包括明显www.example.com的和不太明显的helpdesk.example.com以及webmail.example.com(可能还有其他)。检查区域传输返回的所有名称,并考虑所有与正在评估的目标相关的名称。
尝试owasp.org从其名称服务器之一请求区域传输:
$ host -l www.owasp.org ns1.secure.net
Using domain server:
Name: ns1.secure.net
Address: 192.220.124.10#53
Aliases:
Host www.owasp.org not found: 5(REFUSED)
; Transfer failed.
DNS 反向查询
此过程与前一个过程类似,但依赖于反向 (PTR) DNS 记录。不要请求区域传输,而是尝试将记录类型设置为 PTR 并在给定的 IP 地址上发出查询。如果测试人员幸运的话,他们可能会得到一个 DNS 名称条目。此技术依赖于 IP 到符号名称映射的存在,但不能保证这一点。
基于 Web 的 DNS 搜索
这种搜索类似于 DNS 区域传输,但依赖于在 DNS 上启用基于名称的搜索的基于 Web 的服务。其中一项服务是Netcraft 搜索 DNS服务。测试人员可能会查询属于您选择的域的名称列表,例如example.com. 然后他们将检查他们获得的名称是否与他们正在检查的目标相关。
反向 IP 服务
反向 IP 服务类似于 DNS 反向查询,不同之处在于测试人员查询基于 Web 的应用程序而不是名称服务器。有许多这样的服务可用。由于它们倾向于返回部分(并且通常是不同的)结果,因此最好使用多种服务来获得更全面的分析。
- MxToolbox 反向 IP
- DNSstuff(提供多种服务)
- Net Square(域名和IP地址的多次查询,需要安装)
谷歌搜索
从以前的技术收集信息后,测试人员可以依靠搜索引擎来改进和增加他们的分析。这可能会产生属于目标的其他符号名称的证据,或者可以通过不明显的 URL 访问的应用程序。
例如,考虑前面关于 的示例www.owasp.org,测试人员可以查询 Google 和其他搜索引擎以查找与新发现的域 、 和 相关的信息(因此,DNSwebgoat.org名称webscarab.com)webscarab.net。
谷歌搜索技术在测试:蜘蛛、机器人和爬虫中有解释。
数字证书
如果服务器接受通过 HTTPS 的连接,则证书上的通用名称 (CN) 和主题备用名称 (SAN) 可能包含一个或多个主机名。但是,如果网络服务器没有受信任的证书,或者正在使用通配符,则可能不会返回任何有效信息。
CN和SAN可以通过手动查看证书获取,也可以通过OpenSSL等其他工具获取:
openssl s_client -connect 93.184.216.34:443 </dev/null 2>/dev/null | openssl x509 -noout -text | grep -E 'DNS:|Subject:'
Subject: C = US, ST = California, L = Los Angeles, O = Internet Corporation for Assigned Names and Numbers, CN = www.example.org
DNS:www.example.org, DNS:example.com, DNS:example.edu, DNS:example.net, DNS:example.org, DNS:www.example.com, DNS:www.example.edu, DNS:www.example.net
工具
nslookupDNS 查找工具,例如dig和类似的工具。- 搜索引擎(Google、Bing 和其他主要搜索引擎)。
- 专门的 DNS 相关的基于 Web 的搜索服务:见正文。
- 地图
- Nessus 漏洞扫描程序
- 尼克托
审查源码
https://owasp.org/www-project-web-security-testing-guide/latest/4-Web_Application_Security_Testing/01-Information_Gathering/05-Review_Webpage_Content_for_Information_Leakage
概括
程序员在他们的源代码中包含详细的注释和元数据是很常见的,甚至是被推荐的。但是,HTML 代码中包含的注释和元数据可能会泄露潜在攻击者不应获得的内部信息。应该进行评论和元数据审查以确定是否有任何信息被泄露。此外,某些应用程序可能会在重定向响应正文中泄露信息。
对于现代网络应用程序,前端使用客户端 JavaScript 变得越来越流行。流行的前端构建技术使用客户端 JavaScript,如 ReactJS、AngularJS 或 Vue。与 HTML 代码中的注释和元数据类似,许多程序员也将敏感信息硬编码在前端的 JavaScript 变量中。敏感信息可以包括(但不限于):私有 API 密钥(_例如_不受限制的 Google Map API 密钥)、内部 IP 地址、敏感路由(_例如_到隐藏管理页面或功能的路由),甚至凭据。这些敏感信息可能会从此类前端 JavaScript 代码中泄露。应进行审查,以确定是否有任何敏感信息泄露,可能被攻击者滥用。
对于大型网络应用程序,性能问题是程序员非常关心的问题。程序员使用了不同的方法来优化前端性能,包括 Syntactically Awesome Style Sheets (SASS)、Sassy CSS (SCSS)、webpack 等。使用这些技术,前端代码有时会变得更难理解和难以调试,正因为如此,程序员经常部署源映射文件以进行调试。“源地图”是一种特殊文件,它将资产(CSS 或 JavaScript)的缩小/丑化版本连接到原始创作版本。程序员仍在争论是否将源映射文件带到生产环境中。但是,不可否认的是,如果将源映射文件或用于调试的文件发布到生产环境中,将使它们的源代码更具可读性。它可以使攻击者更容易从前端发现漏洞或从中收集敏感信息。应该进行 JavaScript 代码审查以确定是否有任何调试文件从前端公开。根据项目的上下文和敏感性,安全专家应决定文件是否应存在于生产环境中。
测试目标
- 查看网页评论、元数据和重定向正文以发现任何信息泄漏。
- 收集 JavaScript 文件并查看 JS 代码,以更好地了解应用程序并查找任何信息泄漏。
- 确定源映射文件或其他前端调试文件是否存在。
如何测试
查看网页评论和元数据
开发人员经常使用 HTML 注释来包含有关应用程序的调试信息。有时,他们会忘记评论并将其留在生产环境中。测试人员应该寻找以 开头的 HTML 注释<!--。
检查 HTML 源代码中包含敏感信息的注释,这些信息可以帮助攻击者更深入地了解应用程序。它可能是 SQL 代码、用户名和密码、内部 IP 地址或调试信息。
...
<div class="table2">
<div class="col1">1</div><div class="col2">Mary</div>
<div class="col1">2</div><div class="col2">Peter</div>
<div class="col1">3</div><div class="col2">Joe</div>
<!-- Query: SELECT id, name FROM app.users WHERE active='1' -->
</div>
...
测试人员甚至可能会发现这样的东西:
<!-- Use the DB administrator password for testing: f@keP@a$$w0rD -->
检查 HTML 版本信息以获取有效的版本号和数据类型定义 (DTD) URL
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
strict.dtd– 默认严格 DTDloose.dtd– 宽松的 DTDframeset.dtd– 框架集文档的 DTD
有些META标签不提供主动攻击向量,而是允许攻击者分析应用程序:
<META name="Author" content="Andrew Muller">
一个常见的(但不符合WCAG)META标签是Refresh。
<META http-equiv="Refresh" content="15;URL=https://www.owasp.org/index.html">
标签的一个常见用途META是指定搜索引擎可以用来提高搜索结果质量的关键字。
<META name="keywords" lang="en-us" content="OWASP, security, sunshine, lollipops">
虽然大多数网络服务器通过文件来管理搜索引擎索引robots.txt,但也可以通过META标签来管理。下面的标签将建议机器人不要编制索引,也不要跟踪包含该标签的 HTML 页面上的链接。
<META name="robots" content="none">
互联网内容选择平台 (PICS)和网络描述资源协议 (POWDER)提供了将元数据与互联网内容相关联的基础设施。
识别 JavaScript 代码并收集 JavaScript 文件
程序员经常在前端使用 JavaScript 变量对敏感信息进行硬编码。<script>测试人员应该检查 HTML 源代码并在和标记之间寻找 JavaScript 代码</script>。测试人员还应该识别外部 JavaScript 文件以审查代码(JavaScript 文件的文件扩展名.js和 JavaScript 文件的名称通常放在标签的src(source) 属性中)。<script>
检查 JavaScript 代码是否存在任何敏感信息泄漏,攻击者可以利用这些信息进一步滥用或操纵系统。查找以下值:API 密钥、内部 IP 地址、敏感路由或凭据。例如:
const myS3Credentials = {
accessKeyId: config('AWSS3AccessKeyID'),
secretAcccessKey: config('AWSS3SecretAccessKey'),
};
测试人员甚至可能会发现这样的东西:
var conString = "tcp://postgres:1234@localhost/postgres";
找到 API 密钥后,测试人员可以检查 API 密钥限制是按服务设置的,还是按 IP、HTTP 引荐来源网址、应用程序、SDK 等设置的。
例如,如果测试人员找到 Google Map API 密钥,他们可以检查此 API 密钥是受 IP 限制还是仅受 Google Map API 限制。如果 Google API Key 仅根据 Google Map API 受到限制,攻击者仍然可以使用该 API Key 查询不受限制的 Google Map API,应用程序所有者必须为此付费。
<script type="application/json">
...
{"GOOGLE_MAP_API_KEY":"AIzaSyDUEBnKgwiqMNpDplT6ozE4Z0XxuAbqDi4", "RECAPTCHA_KEY":"6LcPscEUiAAAAHOwwM3fGvIx9rsPYUq62uRhGjJ0"}
...
</script>
在某些情况下,测试人员可能会从 JavaScript 代码中找到敏感路径,例如指向内部或隐藏管理页面的链接。
<script type="application/json">
...
"runtimeConfig":{"BASE_URL_VOUCHER_API":"https://staging-voucher.victim.net/api", "BASE_BACKOFFICE_API":"https://10.10.10.2/api", "ADMIN_PAGE":"/hidden_administrator"}
...
</script>
识别源映射文件
源映射文件通常会在 DevTools 打开时加载。测试人员还可以通过在每个外部 JavaScript 文件的扩展名后添加“.map”扩展名来查找源映射文件。例如,如果测试人员看到一个/static/js/main.chunk.js文件,他们可以通过访问/static/js/main.chunk.js.map.
检查源映射文件中是否有任何敏感信息可以帮助攻击者更深入地了解应用程序。例如:
{
"version": 3,
"file": "static/js/main.chunk.js",
"sources": [
"/home/sysadmin/cashsystem/src/actions/index.js",
"/home/sysadmin/cashsystem/src/actions/reportAction.js",
"/home/sysadmin/cashsystem/src/actions/cashoutAction.js",
"/home/sysadmin/cashsystem/src/actions/userAction.js",
"..."
],
"..."
}
当网站加载源映射文件时,前端源代码将变得可读且更易于调试。
识别泄漏信息的重定向响应
尽管重定向响应通常不会包含任何重要的 Web 内容,但不能保证它们不会包含任何内容。因此,虽然 300 系列(重定向)响应通常包含“重定向到https://example.com/”类型的内容,但它们也可能会泄露内容。
考虑重定向响应是身份验证或授权检查的结果的情况,如果该检查失败,服务器可能会响应将用户重定向回“安全”或“默认”页面,但重定向响应本身可能仍包含内容它没有在浏览器中显示,但确实传输给了客户端。这可以通过利用浏览器开发人员工具或通过个人代理(例如 ZAP、Burp、Fiddler 或 Charles)来实现。
工具
参考
- 钥匙黑客
- RingZer0 在线 CTF - 挑战 104 “管理面板”。
白皮书
确定应用入口点
https://owasp.org/www-project-web-security-testing-guide/latest/4-Web_Application_Security_Testing/01-Information_Gathering/06-Identify_Application_Entry_Points
概括
在进行任何彻底的测试之前,枚举应用程序及其攻击面是一个关键的先决条件,因为它允许测试人员识别可能的弱点区域。本节旨在帮助识别和映射应用程序中的区域,一旦枚举和映射完成后应进行调查。
测试目标
- 通过请求和响应分析确定可能的入口和注入点。
如何测试
在开始任何测试之前,测试人员应该始终很好地了解应用程序,以及用户和浏览器如何与之通信。当测试人员遍历应用程序时,他们应该注意所有 HTTP 请求以及传递给应用程序的每个参数和表单字段。他们应特别注意何时使用 GET 请求以及何时使用 POST 请求向应用程序传递参数。此外,他们还需要注意何时使用其他用于 RESTful 服务的方法。
请注意,为了查看在请求正文(例如 POST 请求)中发送的参数,测试人员可能需要使用诸如拦截代理之类的工具(请参阅工具)。在 POST 请求中,测试人员还应该特别注意传递给应用程序的任何隐藏表单字段,因为这些通常包含敏感信息,例如状态信息、项目数量、项目价格,开发人员永远不会旨在供任何人查看或更改。
根据作者的经验,在这个测试阶段使用拦截代理和电子表格非常有用。代理将在测试人员探索应用程序时跟踪测试人员和应用程序之间的每个请求和响应。此外,在这一点上,测试人员通常会捕获每个请求和响应,以便他们可以准确地看到传递给应用程序的每个标头、参数等以及返回的内容。这有时会非常乏味,尤其是在大型交互式网站上(想想银行应用程序)。然而,经验会告诉我们要寻找什么,这个阶段可以大大减少。
当测试人员遍历应用程序时,他们应该记下 URL、自定义标头或请求/响应正文中的任何有趣参数,并将它们保存在电子表格中。电子表格应包括请求的页面(最好还添加来自代理的请求编号,以供将来参考)、有趣的参数、请求类型(GET、POST 等),如果访问是经过身份验证/未经过身份验证的,如果使用 TLS,如果它是多步骤过程的一部分,如果使用 WebSockets,以及任何其他相关说明。一旦他们规划了应用程序的每个区域,他们就可以检查应用程序并测试他们已经确定的每个区域,并记录哪些有效,哪些无效。本指南的其余部分将确定如何测试每个感兴趣的领域,
以下是所有请求和响应的一些要点。在请求部分,重点关注 GET 和 POST 方法,因为它们出现在大多数请求中。请注意,可以使用其他方法,例如 PUT 和 DELETE。通常,如果允许,这些更罕见的请求可能会暴露漏洞。本指南中有一个专门用于测试这些 HTTP 方法的部分。
要求
- 确定在何处使用 GET 和在何处使用 POST。
- 识别 POST 请求中使用的所有参数(这些在请求的正文中)。
- 在 POST 请求中,请特别注意任何隐藏参数。发送 POST 时,所有表单字段(包括隐藏参数)都将在 HTTP 消息正文中发送到应用程序。这些通常是看不到的,除非使用代理或查看 HTML 源代码。此外,显示的下一页、其数据和访问级别都可能因隐藏参数的值而异。
- 识别 GET 请求中使用的所有参数(即 URL),特别是查询字符串(通常在 ? 标记之后)。
- 识别查询字符串的所有参数。这些通常是成对格式,例如
foo=bar. 另请注意,许多参数可以在一个查询字符串中,例如由&,\~,:或任何其他特殊字符或编码分隔。 - 在识别一个字符串或 POST 请求中的多个参数时需要特别注意的是,执行攻击需要部分或全部参数。测试人员需要识别所有参数(即使已编码或加密)并识别哪些参数由应用程序处理。指南的后面部分将确定如何测试这些参数。在这一点上,只需确保它们中的每一个都被识别出来。
- 还要注意通常看不到的任何其他或自定义类型标头(例如
debug: false)。
回应
- 确定新 cookie 的设置(
Set-Cookie标头)、修改或添加位置。 - 确定在正常响应(即未修改的请求)期间存在任何重定向(3xx HTTP 状态代码)、400 状态代码(尤其是 403 Forbidden)和 500 内部服务器错误的位置。
- 还要注意使用任何有趣的标头的位置。例如,
Server: BIG-IP表示该站点是负载平衡的。因此,如果一个站点是负载平衡的并且一台服务器配置不正确,那么测试人员可能不得不发出多个请求来访问易受攻击的服务器,具体取决于所使用的负载平衡类型。
OWASP 攻击面检测器
Attack Surface Detector (ASD) 工具调查源代码并发现 Web 应用程序的端点、这些端点接受的参数以及这些参数的数据类型。这包括蜘蛛无法找到的未链接端点,或客户端代码中完全未使用的可选参数。它还能够计算应用程序两个版本之间攻击面的变化。
Attack Surface Detector 可作为 ZAP 和 Burp Suite 的插件使用,还提供命令行工具。命令行工具将攻击面导出为 JSON 输出,然后可供 ZAP 和 Burp Suite 插件使用。这对于未直接向渗透测试人员提供源代码的情况很有帮助。例如,渗透测试人员可以从不想提供源代码的客户那里获取 json 输出文件。
如何使用
CLI jar 文件可从https://github.com/secdec/attack-surface-detector-cli/releases下载。
您可以为 ASD 运行以下命令,以从目标 Web 应用程序的源代码中识别端点。
java -jar attack-surface-detector-cli-1.3.5.jar <source-code-path> [flags]
这是针对OWASP RailsGoat运行命令的示例。
$ java -jar attack-surface-detector-cli-1.3.5.jar railsgoat/
Beginning endpoint detection for '<...>/railsgoat' with 1 framework types
Using framework=RAILS
[0] GET: /login (0 variants): PARAMETERS={url=name=url, paramType=QUERY_STRING, dataType=STRING}; FILE=/app/controllers/sessions_contro
ller.rb (lines '6'-'9')
[1] GET: /logout (0 variants): PARAMETERS={}; FILE=/app/controllers/sessions_controller.rb (lines '33'-'37')
[2] POST: /forgot_password (0 variants): PARAMETERS={email=name=email, paramType=QUERY_STRING, dataType=STRING}; FILE=/app/controllers/
password_resets_controller.rb (lines '29'-'38')
[3] GET: /password_resets (0 variants): PARAMETERS={token=name=token, paramType=QUERY_STRING, dataType=STRING}; FILE=/app/controllers/p
assword_resets_controller.rb (lines '19'-'27')
[4] POST: /password_resets (0 variants): PARAMETERS={password=name=password, paramType=QUERY_STRING, dataType=STRING, user=name=user, paramType=QUERY_STRING, dataType=STRING, confirm_password=name=confirm_password, paramType=QUERY_STRING, dataType=STRING}; FILE=/app/controllers/password_resets_controller.rb (lines '5'-'17')
[5] GET: /sessions/new (0 variants): PARAMETERS={url=name=url, paramType=QUERY_STRING, dataType=STRING}; FILE=/app/controllers/sessions_controller.rb (lines '6'-'9')
[6] POST: /sessions (0 variants): PARAMETERS={password=name=password, paramType=QUERY_STRING, dataType=STRING, user_id=name=user_id, paramType=SESSION, dataType=STRING, remember_me=name=remember_me, paramType=QUERY_STRING, dataType=STRING, url=name=url, paramType=QUERY_STRING, dataType=STRING, email=name=email, paramType=QUERY_STRING, dataType=STRING}; FILE=/app/controllers/sessions_controller.rb (lines '11'-'31')
[7] DELETE: /sessions/{id} (0 variants): PARAMETERS={}; FILE=/app/controllers/sessions_controller.rb (lines '33'-'37')
[8] GET: /users (0 variants): PARAMETERS={}; FILE=/app/controllers/api/v1/users_controller.rb (lines '9'-'11')
[9] GET: /users/{id} (0 variants): PARAMETERS={}; FILE=/app/controllers/api/v1/users_controller.rb (lines '13'-'15')
... snipped ...
[38] GET: /api/v1/mobile/{id} (0 variants): PARAMETERS={id=name=id, paramType=QUERY_STRING, dataType=STRING, class=name=class, paramType=QUERY_STRING, dataType=STRING}; FILE=/app/controllers/api/v1/mobile_controller.rb (lines '8'-'13')
[39] GET: / (0 variants): PARAMETERS={url=name=url, paramType=QUERY_STRING, dataType=STRING}; FILE=/app/controllers/sessions_controller.rb (lines '6'-'9')
Generated 40 distinct endpoints with 0 variants for a total of 40 endpoints
Successfully validated serialization for these endpoints
0 endpoints were missing code start line
0 endpoints were missing code end line
0 endpoints had the same code start and end line
Generated 36 distinct parameters
Generated 36 total parameters
- 36/36 have their data type
- 0/36 have a list of accepted values
- 36/36 have their parameter type
--- QUERY_STRING: 35
--- SESSION: 1
Finished endpoint detection for '<...>/railsgoat'
----------
-- DONE --
0 projects had duplicate endpoints
Generated 40 distinct endpoints
Generated 40 total endpoints
Generated 36 distinct parameters
Generated 36 total parameters
1/1 projects had endpoints generated
To enable logging include the -debug argument
您还可以使用-json标志生成一个 JSON 输出文件,插件可以将其用于 ZAP 和 Burp Suite。有关详细信息,请参阅以下链接。
测试应用程序入口点
以下是有关如何检查应用程序入口点的两个示例。
示例 1
此示例显示了一个 GET 请求,该请求将从在线购物应用程序中购买商品。
GET /shoppingApp/buyme.asp?CUSTOMERID=100&ITEM=z101a&PRICE=62.50&IP=x.x.x.x HTTP/1.1
Host: x.x.x.x
Cookie: SESSIONID=Z29vZCBqb2IgcGFkYXdhIG15IHVzZXJuYW1lIGlzIGZvbyBhbmQgcGFzc3dvcmQgaXMgYmFy
请求的所有参数,如 CUSTOMERID、ITEM、PRICE、IP 和 Cookie,这些参数可以只是编码参数或用于会话状态的参数。
示例 2
此示例显示了一个 POST 请求,该请求将使您登录到应用程序。
POST /example/authenticate.asp?service=login HTTP/1.1
Host: x.x.x.x
Cookie: SESSIONID=dGhpcyBpcyBhIGJhZCBhcHAgdGhhdCBzZXRzIHByZWRpY3RhYmxlIGNvb2tpZXMgYW5kIG1pbmUgaXMgMTIzNA==;CustomCookie=00my00trusted00ip00is00x.x.x.x00
user=admin&pass=pass123&debug=true&fromtrustIP=true
可以注意到参数在几个位置发送:
- 在查询字符串中:
service - 在 Cookie 标头中:
SESSIONID,CustomCookie - 在请求正文中:
user,pass,debug,fromtrustIP
拥有各种注入位置为攻击者提供了链接的可能性,可以提高在处理代码中发现错误的机会。
工具
参考
通过应用映射执行路径
https://owasp.org/www-project-web-security-testing-guide/latest/4-Web_Application_Security_Testing/01-Information_Gathering/07-Map_Execution_Paths_Through_Application
概括
在开始安全测试之前,了解应用程序的结构至关重要。如果对应用程序的布局没有透彻的了解,就不可能对其进行彻底的测试。
测试目标
- 映射目标应用程序并了解主要工作流。
如何测试
在黑盒测试中,测试整个代码库是极其困难的。不仅仅是因为测试人员看不到应用程序的代码路径,而且即使他们看到了,测试所有代码路径也会非常耗时。协调这一点的一种方法是记录发现和测试的代码路径。
有几种方法可以测试和测量代码覆盖率:
- PATH - 测试通过应用程序的每条路径,包括针对每条决策路径的组合和边界值分析测试。虽然这种方法提供了彻底性,但可测试路径的数量随着每个决策分支呈指数增长。
- Data Flow (or Taint Analysis) - 通过外部交互(通常是用户)测试变量的分配。专注于映射整个应用程序中数据的流动、转换和使用。
- Race - 测试处理相同数据的应用程序的多个并发实例。
应与应用程序所有者协商权衡使用何种方法以及每种方法的使用程度。也可以采用更简单的方法,包括询问应用程序所有者他们特别关注哪些功能或代码段以及如何到达这些代码段。
为了向应用程序所有者展示代码覆盖率,测试人员可以从电子表格开始并记录通过爬取应用程序(手动或自动)发现的所有链接。然后,测试人员可以更仔细地查看应用程序中的决策点,并调查发现了多少重要的代码路径。然后应将这些记录在电子表格中,其中包含所发现路径的 URL、散文和屏幕截图描述。
自动抓取
自动蜘蛛是一种用于自动发现特定网站上的新资源(URL)的工具。它以要访问的 URL 列表开始,称为种子,这取决于 Spider 的启动方式。虽然有很多 Spidering 工具,但以下示例使用Zed Attack Proxy (ZAP):
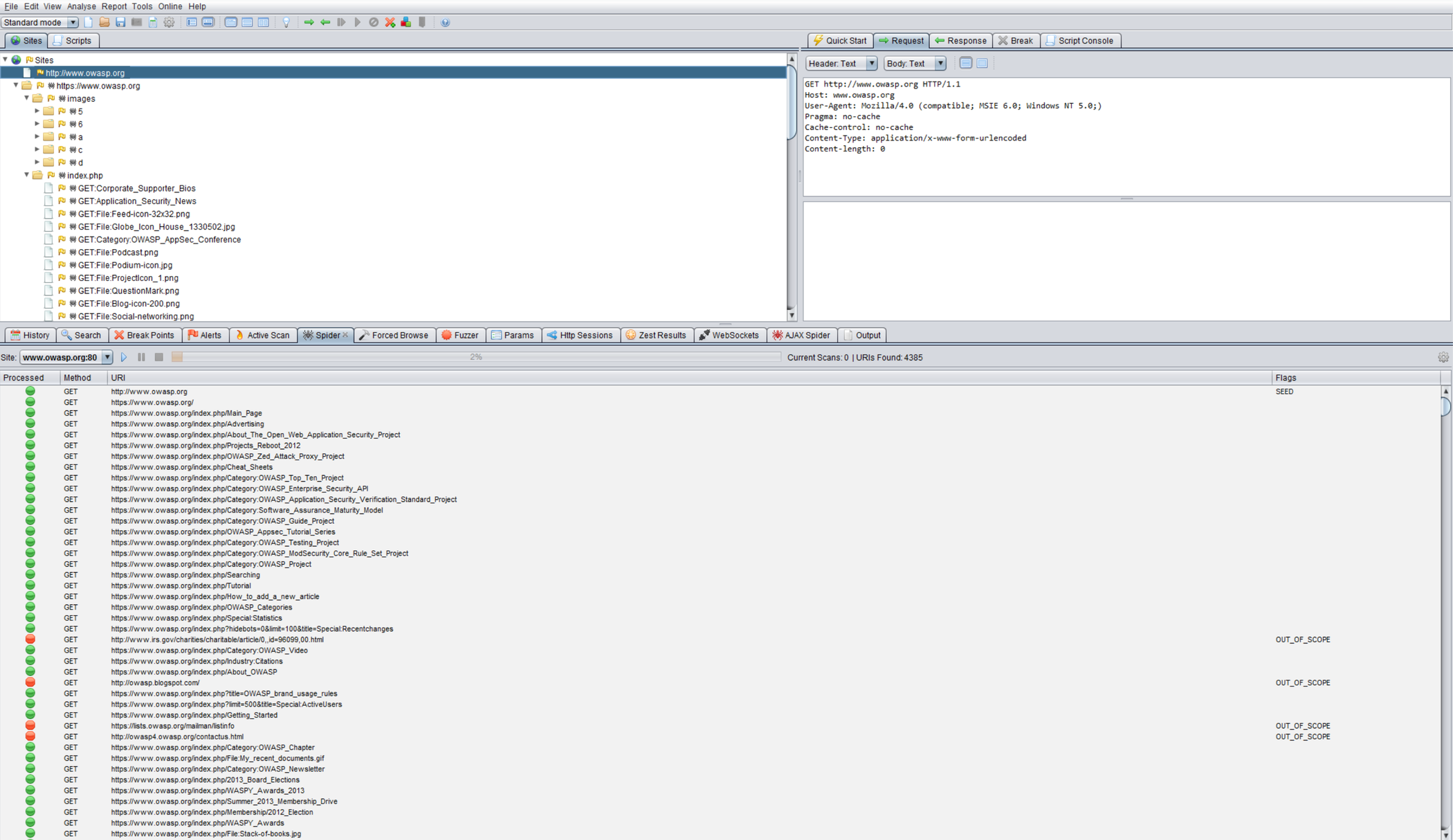
图 4.1.7-1:Zed 攻击代理屏幕
ZAP提供各种自动爬取选项,可以根据测试人员的需要加以利用:
工具
参考
WEB应用指纹识别
https://owasp.org/www-project-web-security-testing-guide/latest/4-Web_Application_Security_Testing/01-Information_Gathering/08-Fingerprint_Web_Application_Framework
概括
太阳底下没有新鲜事,人们可能想到要开发的几乎所有 Web 应用程序都已经开发出来了。随着世界各地积极开发和部署的大量免费和开源软件项目,应用程序安全测试很可能会面临一个完全或部分依赖于这些众所周知的应用程序或框架(例如 WordPress 、phpBB、Mediawiki 等)。了解正在测试的 Web 应用程序组件对测试过程有很大帮助,也将大大减少测试期间所需的工作量。这些众所周知的 Web 应用程序具有众所周知的 HTML 标头、cookie 和目录结构,可以通过枚举来识别这些应用程序。大多数 Web 框架在这些位置都有几个标记,可以帮助攻击者或测试者识别它们。这基本上是所有自动工具所做的,它们从预定义的位置寻找标记,然后将其与已知签名的数据库进行比较。为了获得更好的准确性,通常使用多个标记。
测试目标
- 对 Web 应用程序使用的组件进行指纹识别。
如何测试
黑盒测试
为了识别框架或组件,需要考虑几个常见的位置:
- HTTP 标头
- 饼干
- 网页源代码
- 特定文件和文件夹
- 文件扩展名
- 错误讯息
HTTP 标头
识别 Web 框架的最基本形式是查看X-Powered-ByHTTP 响应标头中的字段。许多工具都可以用来对目标进行指纹识别,最简单的是netcat。
考虑以下 HTTP 请求-响应:
$ nc 127.0.0.1 80
HEAD / HTTP/1.0
HTTP/1.1 200 OK
Server: nginx/1.0.14
[...]
X-Powered-By: Mono
从X-Powered-By现场,我们了解到 Web 应用程序框架很可能是Mono. 然而,虽然这种方法简单快捷,但这种方法并不是在 100% 的情况下都有效。X-Powered-By可以通过适当的配置轻松禁用标头。还有几种技术可以让网站混淆 HTTP 标头(请参阅修复部分中的示例)。nginx在上面的示例中,我们还可以注意到正在使用的特定版本来提供内容。
因此,在同一个示例中,测试人员可能会错过X-Powered-By标头或获得如下所示的答案:
HTTP/1.1 200 OK
Server: nginx/1.0.14
Date: Sat, 07 Sep 2013 08:19:15 GMT
Content-Type: text/html;charset=ISO-8859-1
Connection: close
Vary: Accept-Encoding
X-Powered-By: Blood, sweat and tears
有时会有更多的 HTTP 标头指向某个框架。在下面的例子中,根据 HTTP 请求的信息,可以看到X-Powered-Byheader 中包含 PHP 版本。然而,X-Generator标头指出使用的框架实际上是Swiftlet,这有助于渗透测试人员扩展他们的攻击向量。执行指纹识别时,请仔细检查每个 HTTP 标头是否存在此类泄漏。
HTTP/1.1 200 OK
Server: nginx/1.4.1
Date: Sat, 07 Sep 2013 09:22:52 GMT
Content-Type: text/html
Connection: keep-alive
Vary: Accept-Encoding
X-Powered-By: PHP/5.4.16-1~dotdeb.1
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0
Pragma: no-cache
X-Generator: Swiftlet
Cookie
确定当前 Web 框架的另一种类似且更可靠的方法是特定于框架的 cookie。
考虑以下 HTTP 请求:

图 4.1.8-7:Cakephp HTTP 请求
cookieCAKEPHP已自动设置,它提供有关正在使用的框架的信息。Cookie部分列出了常见的 cookie 名称。依赖这种识别机制仍然存在局限性——可以更改 cookie 的名称。例如,对于选定的CakePHP框架,这可以通过以下配置完成(摘自core.php):
/**
* The name of CakePHP's session cookie.
*
* Note the guidelines for Session names states: "The session name references
* the session id in cookies and URLs. It should contain only alphanumeric
* characters."
* @link http://php.net/session_name
*/
Configure::write('Session.cookie', 'CAKEPHP');
但是,与标头的更改相比,进行这些更改的可能性较小X-Powered-By,因此可以认为这种识别方法更可靠。
HTML 源代码
此技术基于在 HTML 页面源代码中查找某些模式。人们通常可以找到很多信息来帮助测试人员识别特定组件。一种常见的标记是直接导致框架泄露的 HTML 注释。通常可以找到某些特定于框架的路径,即指向特定于框架的 CSS 或 JS 文件夹的链接。最后,特定的脚本变量也可能指向某个框架。
从下面的屏幕截图中,可以通过提到的标记轻松了解使用的框架及其版本。注释、具体路径和脚本变量都可以帮助攻击者快速确定ZK框架的实例。

图 4.1.8-2:ZK 框架 HTML 源代码示例
此类信息通常位于<head>HTTP 响应部分、<meta>标记中或页面末尾。然而,应该分析整个响应,因为它可以用于其他目的,例如检查其他有用的评论和隐藏字段。有时,Web 开发人员不太关心隐藏有关所用框架或组件的信息。仍然有可能在页面底部偶然发现类似这样的内容:

图 4.1.8-3:Banshee 底部页面
特定文件和文件夹
还有另一种方法可以极大地帮助攻击者或测试者高精度地识别应用程序或组件。每个 Web 组件在服务器上都有自己特定的文件和文件夹结构。已经注意到,可以从 HTML 页面源代码中看到特定路径,但有时它们并没有明确地显示在那里,而是仍然驻留在服务器上。
为了发现它们,使用了一种称为强制浏览或“dirbusting”的技术。Dirbusting 是暴力破解具有已知文件夹和文件名的目标,并监视 HTTP 响应以枚举服务器内容。此信息既可用于查找默认文件和攻击它们,也可用于对 Web 应用程序进行指纹识别。Dirbusting 可以通过多种方式完成,下面的示例显示了在 Burp Suite 的定义列表和入侵者功能的帮助下,对 WordPress 支持的目标进行成功的 dirbusting 攻击。

图 4.1.8-4:使用 Burp 进行分发
我们可以看到,对于某些特定于 WordPress 的文件夹(例如,/wp-includes/和/wp-admin/) , /wp-content/HTTP 响应分别为 403(禁止访问)、302(找到,重定向到 wp-login.php)和 200(确定)。这是一个很好的指标,表明目标是由 WordPress 驱动的。以同样的方式可以 dirbust 不同的应用程序插件文件夹及其版本。在下面的屏幕截图中,可以看到一个典型的 Drupal 插件的 CHANGELOG 文件,它提供了有关正在使用的应用程序的信息,并揭示了一个易受攻击的插件版本。
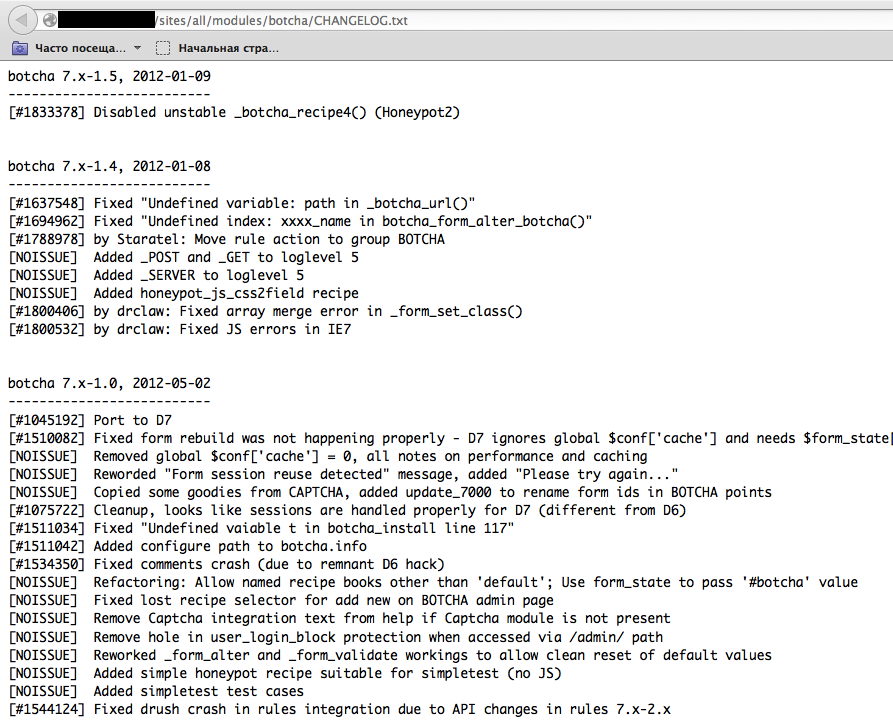
图 4.1.8-5:Drupal Botcha 披露
提示:在开始 dirbusting 之前,请先检查robots.txt文件。有时也可以在那里找到特定于应用程序的文件夹和其他敏感信息。robots.txt下面的屏幕截图显示了此类文件的示例。
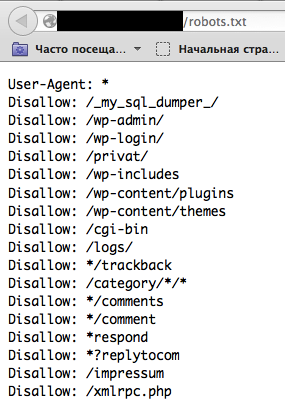
图 4.1.8-6:机器人信息公开
每个特定应用程序的特定文件和文件夹都不同。如果确定的应用程序或组件是开源的,则在渗透测试期间设置临时安装可能有价值,以便更好地了解所提供的基础设施或功能,以及服务器上可能留下的文件。但是,已经存在几个不错的文件列表;一个很好的例子是可预测文件/文件夹的 FuzzDB 词表。
文件扩展名
URL 可能包含文件扩展名,这也有助于识别网络平台或技术。
例如,OWASP wiki 使用 PHP:
https://wiki.owasp.org/index.php?title=Fingerprint_Web_Application_Framework&action=edit§ion=4
以下是一些常见的 Web 文件扩展名和相关技术:
.php– PHP.aspx– 微软 ASP.NET.jsp– Java 服务器页面
错误信息
如以下屏幕截图所示,列出的文件系统路径指向使用 WordPress ( wp-content)。测试人员还应该知道 WordPress 是基于 PHP 的 ( functions.php)。
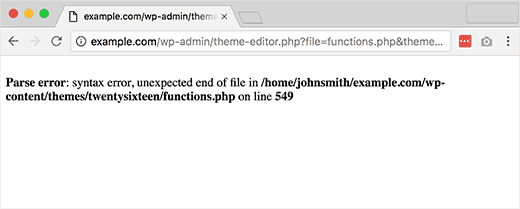
图 4.1.8-7:WordPress 解析错误
通用标识符
Cookie
Framework Cookie name
Zope zope3
CakePHP cakephp
Kohana kohanasession
Laravel laravel_session
phpBB phpbb3_
WordPress wp-settings
1C-Bitrix BITRIX_
AMPcms AMP
Django CMS django
DotNetNuke DotNetNukeAnonymous
e107 e107_tz
EPiServer EPiTrace, EPiServer
Graffiti CMS graffitibot
Hotaru CMS hotaru_mobile
ImpressCMS ICMSession
Indico MAKACSESSION
InstantCMS InstantCMS[logdate]
Kentico CMS CMSPreferredCulture
MODx SN4[12symb]
TYPO3 fe_typo_user
Dynamicweb Dynamicweb
LEPTON lep[some_numeric_value]+sessionid
Wix Domain=.wix.com
VIVVO VivvoSessionId
HTML 源代码
应用
关键词
WordPress的
<meta name="generator" content="WordPress 3.9.2" />
phpBB
<body id="phpbb"
Mediawiki
<meta name="generator" content="MediaWiki 1.21.9" />
Joomla
<meta name="generator" content="Joomla! - Open Source Content Management" />
Drupal
<meta name="Generator" content="Drupal 7 (http://drupal.org)" />
DotNetNuke
DNN Platform - [http://www.dnnsoftware.com](http://www.dnnsoftware.com)
一般标记
%framework_name%powered bybuilt uponrunning
特定标记
框架
关键词
Adobe ColdFusion
<!-- START headerTags.cfm
Microsoft ASP.NET
__VIEWSTATE
ZK
<!-- ZK
Business Catalyst
<!-- BC_OBNW -->
Indexhibit
ndxz-studio
整治
虽然可以努力使用不同的 cookie 名称(通过更改配置)、隐藏或更改文件/目录路径(通过重写或源代码更改)、删除已知标头等,但这些努力归结为“通过模糊实现安全”。系统所有者/管理员应该认识到,这些努力只会减慢最基本的对手。时间/精力可以更好地用于利益相关者意识和解决方案维护活动。
工具
下面列出了常用和众所周知的工具。还有很多其他实用程序,以及基于框架的指纹识别工具。
Whatweb
网站:https ://github.com/urbanadventurer/WhatWeb
目前市场上最好的指纹识别工具之一。包含在默认的Kali Linux构建中。语言:Ruby 用于指纹识别的匹配使用:
- 文本字符串(区分大小写)
- 常用表达
- Google Hack 数据库查询(有限的关键字集)
- MD5 哈希
- 网址识别
- HTML 标记模式
- 用于被动和主动操作的自定义 ruby 代码
示例输出显示在下面的屏幕截图中:
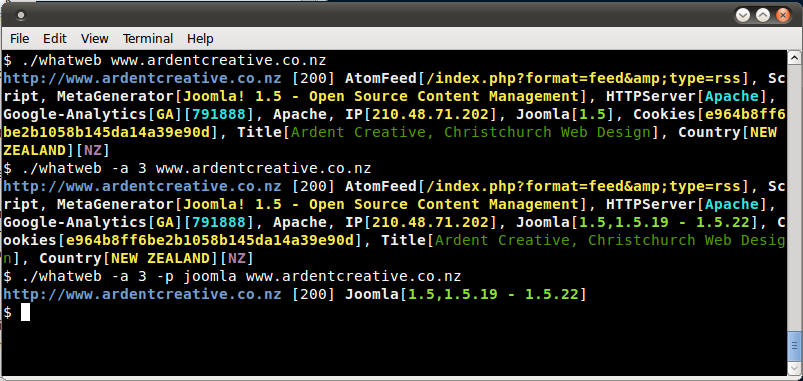
图 4.1.8-8:Whatweb 输出示例
Wappalyzer
网站:https ://www.wappalyzer.com/
Wappalyzer 有多种使用模式,其中最流行的可能是 Firefox/Chrome 扩展。它们仅适用于正则表达式匹配,除了要在浏览器中加载的页面外,不需要任何其他内容。它完全在浏览器级别工作,并以图标的形式给出结果。虽然有时它会出现误报,但在浏览页面后立即了解使用了哪些技术来构建目标网站非常方便。
下面的屏幕截图显示了插件的示例输出。
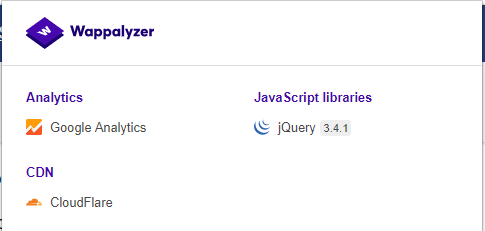
图 4.1.8-9:OWASP 网站的 Wappalyzer 输出
参考
白皮书
WEB服务器指纹识别
https://owasp.org/www-project-web-security-testing-guide/latest/4-Web_Application_Security_Testing/01-Information_Gathering/02-Fingerprint_Web_Server
概括
Web 服务器指纹识别是识别运行目标的 Web 服务器的类型和版本的任务。虽然 Web 服务器指纹通常封装在自动化测试工具中,但对于研究人员来说,了解这些工具如何尝试识别软件的基本原理及其有用的原因非常重要。
准确地发现运行应用程序的 Web 服务器的类型可以使安全测试人员确定应用程序是否容易受到攻击。特别是,运行没有最新安全补丁的旧版本软件的服务器可能容易受到已知版本特定漏洞的攻击。
测试目标
- 确定正在运行的 Web 服务器的版本和类型,以便进一步发现任何已知漏洞。
如何测试
用于 Web 服务器指纹识别的技术包括banner抓取、引发对格式错误的请求的响应,以及使用自动化工具执行使用策略组合的更强大的扫描。所有这些技术运作的基本前提是相同的。他们都努力从 Web 服务器中引出一些响应,然后可以将这些响应与已知响应和行为的数据库进行比较,从而与已知的服务器类型相匹配。
banner 抓取
banner抓取是通过向 Web 服务器发送 HTTP 请求并检查其响应标头来执行的。这可以使用各种工具来完成,包括telnetHTTP 请求或openssl通过 TLS/SSL 的请求。
例如,这是对来自 Apache 服务器的请求的响应。
HTTP/1.1 200 OK
Date: Thu, 05 Sep 2019 17:42:39 GMT
Server: Apache/2.4.41 (Unix)
Last-Modified: Thu, 05 Sep 2019 17:40:42 GMT
ETag: "75-591d1d21b6167"
Accept-Ranges: bytes
Content-Length: 117
Connection: close
Content-Type: text/html
...
这是另一个响应,这次来自 nginx。
HTTP/1.1 200 OK
Server: nginx/1.17.3
Date: Thu, 05 Sep 2019 17:50:24 GMT
Content-Type: text/html
Content-Length: 117
Last-Modified: Thu, 05 Sep 2019 17:40:42 GMT
Connection: close
ETag: "5d71489a-75"
Accept-Ranges: bytes
...
这是来自 lighttpd 的响应。
HTTP/1.0 200 OK
Content-Type: text/html
Accept-Ranges: bytes
ETag: "4192788355"
Last-Modified: Thu, 05 Sep 2019 17:40:42 GMT
Content-Length: 117
Connection: close
Date: Thu, 05 Sep 2019 17:57:57 GMT
Server: lighttpd/1.4.54
在这些例子中,服务器类型和版本被清楚地暴露了。但是,注重安全的应用程序可能会通过修改标头来混淆其服务器信息。例如,以下是对具有修改标头的站点请求的响应的摘录:
HTTP/1.1 200 OK
Server: Website.com
Date: Thu, 05 Sep 2019 17:57:06 GMT
Content-Type: text/html; charset=utf-8
Status: 200 OK
...
在服务器信息模糊不清的情况下,测试人员可能会根据标头字段的顺序猜测服务器的类型。请注意,在上面的 Apache 示例中,字段遵循以下顺序:
- 日期
- 服务器
- 最后修改
- 电子标签
- 接受范围
- 内容长度
- 联系
- 内容类型
但是,在 nginx 和模糊服务器示例中,共同的字段都遵循以下顺序:
- 服务器
- 日期
- 内容类型
测试人员可以根据这些信息猜测被遮挡的服务器是nginx。但是,考虑到多个不同的Web服务器可能共享相同的字段顺序并且可以修改或删除字段,这种方法是不确定的。
发送格式错误的请求
Web 服务器可以通过检查它们的错误响应来识别,并且在它们没有被定制的情况下,它们的默认错误页面。强制服务器呈现这些内容的一种方法是故意发送不正确或格式错误的请求。
例如,这是对SANTA CLAUS来自 Apache 服务器的不存在方法的请求的响应。
GET / SANTA CLAUS/1.1
HTTP/1.1 400 Bad Request
Date: Fri, 06 Sep 2019 19:21:01 GMT
Server: Apache/2.4.41 (Unix)
Content-Length: 226
Connection: close
Content-Type: text/html; charset=iso-8859-1
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>400 Bad Request</title>
</head><body>
<h1>Bad Request</h1>
<p>Your browser sent a request that this server could not understand.<br />
</p>
</body></html>
这是对来自 nginx 的相同请求的响应。
GET / SANTA CLAUS/1.1
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx/1.17.3</center>
</body>
</html>
这是对来自 lighttpd 的相同请求的响应。
GET / SANTA CLAUS/1.1
HTTP/1.0 400 Bad Request
Content-Type: text/html
Content-Length: 345
Connection: close
Date: Sun, 08 Sep 2019 21:56:17 GMT
Server: lighttpd/1.4.54
<?xml version="1.0" encoding="iso-8859-1"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>400 Bad Request</title>
</head>
<body>
<h1>400 Bad Request</h1>
</body>
</html>
由于默认错误页面在不同类型的 Web 服务器之间提供了许多区分因素,因此即使在服务器标头字段被遮盖的情况下,它们的检查也可以成为指纹识别的有效方法。
使用自动扫描工具
如前所述,Web 服务器指纹识别通常作为自动扫描工具的一项功能包含在内。这些工具能够发出类似于上面演示的请求,以及发送其他更特定于服务器的探测。自动化工具可以比手动测试更快地比较来自 Web 服务器的响应,并利用已知响应的大型数据库来尝试识别服务器。由于这些原因,自动化工具更有可能产生准确的结果。
以下是一些包含 Web 服务器指纹识别功能的常用扫描工具。
整治
虽然暴露的服务器信息本身不一定是漏洞,但它是可以帮助攻击者利用可能存在的其他漏洞的信息。暴露的服务器信息还可能导致攻击者找到特定于版本的服务器漏洞,这些漏洞可用于利用未打补丁的服务器。因此,建议采取一些预防措施。这些行动包括:
- 隐藏标头中的 Web 服务器信息,例如使用 Apache 的mod_headers 模块。
- 使用加固的反向代理服务器在 Web 服务器和 Internet 之间创建额外的安全层。
- 确保 Web 服务器与最新的软件和安全补丁保持同步。
MAP 应用框架
概括
为了有效地测试应用程序,并能够就如何解决任何已识别的问题提供有意义的建议,了解您实际测试的内容非常重要。此外,它还可以帮助确定是否应将特定组件视为超出测试范围。
现代 Web 应用程序的复杂性可能有很大差异,从在单个服务器上运行的简单脚本到跨数十种不同系统、语言和组件的高度复杂的应用程序。还可能有额外的网络级组件,例如防火墙或入侵保护系统,它们会对测试产生重大影响。
测试目标
- 了解应用程序的架构和使用的技术。
如何测试
从黑盒角度进行测试时,重要的是要尝试清楚地了解应用程序的工作方式,以及采用了哪些技术和组件。在某些情况下,可以测试特定组件(例如 Web 应用程序防火墙),而其他情况则可以通过检查应用程序的行为来识别。
以下部分提供了对常见架构组件的高级概述,以及如何识别它们的详细信息。
应用组件
网络服务器
简单的应用程序可能会在单个服务器上运行,这可以使用指南的指纹 Web 服务器部分中讨论的步骤来识别。
平台即服务 (PaaS)
在平台即服务 (PaaS) 模型中,Web 服务器和底层基础设施由服务提供商管理,客户只对部署在其上的应用程序负责。从测试的角度来看,有两个主要区别:
- 应用程序所有者无权访问底层基础设施,因此无法直接修复任何问题。
- 基础设施测试很可能超出任何项目的范围。
在某些情况下,可以识别 PaaS 的使用,因为应用程序可能使用特定的域名(例如,部署在 Azure App Services 上的应用程序将有一个*.azurewebsites.net域——尽管它们也可能使用自定义域)。但是,在其他情况下,很难确定是否正在使用 PaaS。
无服务器
在无服务器模型中,开发人员提供直接在托管平台上作为独立功能运行的代码,而不是作为部署在 webroot 中的传统大型 Web 应用程序。这使得它非常适合基于微服务的架构。与 PaaS 环境一样,基础架构测试可能超出范围。
在某些情况下,可能会通过特定 HTTP 标头的存在来指示无服务器代码的使用。例如,AWS Lambda 函数通常会返回以下标头:
X-Amz-Invocation-Type
X-Amz-Log-Type
X-Amz-Client-Context
Azure Functions 不太明显。它们通常会返回Server: Kestrel标头 - 但这本身并不足以确信它是一个 Azure 应用程序函数,而不是在 Kestrel 上运行的一些其他代码。
微服务
在基于微服务的架构中,应用程序 API 由多个离散服务组成,而不是作为一个整体应用程序运行。服务本身通常在容器内运行(通常使用 Kubernetes),并且可以使用各种不同的操作系统和语言。尽管它们通常位于单个 API 网关和域之后,但使用多种语言(通常在详细的错误消息中指出)可能表明正在使用微服务。
静态存储
许多应用程序将静态内容存储在专用存储平台上,而不是直接托管在主 Web 服务器上。两个最常见的平台是 Amazon 的 S3 Buckets 和 Azure 的 Storage Accounts,可以通过域名轻松识别:
- Amazon S3 存储桶是
BUCKET.s3.amazonaws.com或s3.REGION.amazonaws.com/BUCKET - Azure 存储帐户是
ACCOUNT.blob.core.windows.net
这些存储帐户通常会暴露敏感文件,如测试云存储指南部分所述。
数据库
大多数重要的 Web 应用程序使用某种数据库来存储动态内容。在某些情况下,可以确定数据库,尽管它通常依赖于应用程序中的其他问题。这通常可以通过以下方式完成:
- 端口扫描服务器并查找与特定数据库关联的任何开放端口。
- 触发与 SQL(或 NoSQL)相关的错误消息(或从搜索引擎中查找现有错误。
如果无法最终确定数据库,您通常可以根据应用程序的其他方面进行有根据的猜测:
- Windows、IIS 和 ASP.NET 经常使用 Microsoft SQL 服务器。
- 嵌入式系统通常使用 SQLite。
- PHP 通常使用 MySQL 或 PostgreSQL。
- APEX 经常使用 Oracle。
这些不是硬性规定,但如果没有更好的信息,肯定可以为您提供一个合理的起点。
验证
大多数应用程序都有某种形式的用户身份验证。可以使用多种身份验证后端,例如:
- Web 服务器配置(包括
.htaccess文件)或脚本中的硬编码密码。- 通常显示为 HTTP 基本身份验证,由浏览器中的弹出窗口和
WWW-Authenticate: BasicHTTP 标头指示。
- 通常显示为 HTTP 基本身份验证,由浏览器中的弹出窗口和
- 数据库中的本地用户帐户。
- 通常集成到应用程序的表单或 API 端点中。
- 现有的中央身份验证源,例如 Active Directory 或 LDAP 服务器。
- 可以使用 NTLM 身份验证,由
WWW-Authenticate: NTLMHTTP 标头指示。 - 可以以一种形式集成到 Web 应用程序中。
- 可能需要以“DOMAIN\username”格式输入用户名,或者可能会提供可用域的下拉列表。
- 可以使用 NTLM 身份验证,由
- 与内部或外部提供商的单点登录 (SSO)。
- 通常使用 OAuth、OpenID Connect 或 SAML。
应用程序可能会为用户提供多种身份验证选项(例如注册本地帐户或使用他们现有的 Facebook 帐户),并且可能会为普通用户和管理员使用不同的机制。
第三方服务和 API
几乎所有 Web 应用程序都包含由客户端加载或与之交互的第三方资源。这些可以包括:
这些资源直接由用户的浏览器请求,因此可以使用开发人员工具或拦截代理轻松识别。虽然识别它们很重要(因为它们会影响应用程序的安全性),但请记住_它们通常不在测试范围内_,因为它们属于第三方。
网络组件
反向代理
反向代理位于一个或多个后端服务器之前,并将请求重定向到适当的目的地。它们可以实现各种功能,例如:
- 充当负载平衡器或Web 应用程序防火墙。
- 允许多个应用程序托管在单个 IP 地址或域(在子文件夹中)。
- 实施 IP 过滤或其他限制。
- 从后端缓存内容以提高性能。
并非总能检测到反向代理(特别是如果它后面只有一个应用程序),但有时您通常可以通过以下方式识别它:
- 前端服务器和后端应用程序之间的不匹配(例如
Server: nginx带有 ASP.NET 应用程序的标头)。- 这有时会导致请求走私漏洞。
- 重复的标头(尤其是
Server标头)。 - 在同一 IP 地址或域上托管多个应用程序(尤其是当它们使用不同语言时)。
负载均衡器
负载均衡器位于多个后端服务器之前,并在它们之间分配请求,以便为应用程序提供更大的冗余和处理能力。
负载均衡器可能难以检测,但有时可以通过发出多个请求并检查响应的差异来识别,例如:
- 系统时间不一致。
- 详细错误消息中的不同内部 IP 地址或主机名。
- 从服务器端请求伪造 (SSRF)返回的不同地址。
它们也可以通过特定 cookie 的存在来指示(例如,F5 BIG-IP 负载平衡器将创建一个名为BIGipServer.
内容分发网络 (CDN)
内容分发网络 (CDN) 是一组地理分布的缓存代理服务器,旨在提高网站性能,为网站提供额外的弹性。
它通常通过将面向公众的域指向 CDN 的服务器,然后配置 CDN 以连接到正确的后端服务器(有时称为“源”)来配置。
检测 CDN 的最简单方法是对域解析到的 IP 地址执行 WHOIS 查询。如果他们属于 CDN 公司(例如 Akamai、Cloudflare 或 Fastly - 请参阅维基百科以获取更完整的列表),那么就好像正在使用 CDN。
在 CDN 后面测试站点时,您应该牢记以下几点:
- IP 和服务器属于 CDN 提供商,很可能不在基础设施测试范围内。
- 许多 CDN 还包括机器人检测、速率限制和 Web 应用程序防火墙等功能。
- CDN 通常缓存内容,因此对后端网站所做的任何更改可能不会立即显示。
如果该站点位于 CDN 后面,则识别后端服务器会很有用。如果他们没有实施适当的访问控制,那么您可以通过直接访问后端服务器来绕过 CDN(及其提供的任何保护)。有多种不同的方法可以让您识别后端系统:
- 应用程序发送的电子邮件可能直接来自后端服务器,这可能会泄露其 IP 地址。
- 域的 DNS 研磨、区域传输或证书透明列表可能会在子域上显示它。
- 扫描公司已知使用的 IP 范围可能会找到后端服务器。
- 利用服务器端请求伪造 (SSRF)可能会泄露 IP 地址。
- 来自应用程序的详细错误消息可能会暴露 IP 地址或主机名。
安全组件
网络防火墙
大多数 Web 服务器将受到数据包过滤或状态检测防火墙的保护,这些防火墙会阻止任何不需要的网络流量。要检测到这一点,请对服务器执行端口扫描并检查结果。
如果大多数端口显示为“关闭”(即,它们返回一个RST数据包以响应初始SYN数据包),则这表明服务器可能不受防火墙保护。如果端口显示为“已过滤”(即,将数据包发送到未使用的端口时未收到响应SYN),则很可能存在防火墙。
此外,如果向世界公开了不适当的服务(例如 SMTP、IMAP、MySQL 等),这表明要么没有适当的防火墙,要么防火墙配置不当。
网络入侵检测与防御系统
网络入侵检测系统 (IDS) 检测可疑或恶意的网络级活动(例如端口或漏洞扫描)并发出警报。入侵防御系统 (IPS) 与此类似,但也会采取措施阻止活动 - 通常是通过阻止源 IP 地址。
通常可以通过针对目标运行自动扫描工具(例如端口扫描器)并查看源 IP 是否被阻止来检测 IPS。然而,许多应用程序级工具可能无法被 IPS 检测到(特别是如果它不解密 TLS)。
Web 应用程序防火墙 (WAF)
Web 应用程序防火墙 (WAF) 检查 HTTP 请求的内容并阻止那些看似可疑或恶意的请求,或动态应用其他控制,例如 CAPTCHA 或速率限制。它们通常基于一组已知的错误签名和正则表达式,例如OWASP 核心规则集。WAF 可以有效地防范某些类型的攻击(例如 SQL 注入或跨站点脚本),但对其他类型的攻击(例如访问控制或业务逻辑相关问题)则效果较差。
WAF 可以部署在多个位置,包括:
- 在 Web 服务器本身上。
- 在单独的虚拟机或硬件设备上。
- 在后端服务器前面的云端。
因为WAF拦截了恶意请求,所以可以通过在参数中加入常见的攻击字符串,观察是否被拦截来检测。例如,尝试添加一个名为或foo之类的参数。如果这些请求被阻止,则表明可能存在 WAF。此外,块页面的内容可以提供有关正在使用的特定技术的信息。最后,某些 WAF 可能会将 cookie 或 HTTP 标头添加到可以显示其存在的响应中。' UNION SELECT 1``><script>alert(1)</script>
如果正在使用基于云的 WAF,则可以通过直接访问后端服务器来绕过它,使用内容交付网络部分中讨论的相同方法。