对信息泄露进行搜索引擎发现侦察
概括
为了让搜索引擎工作,计算机程序(或)定期从网络上的数十亿页面中robots获取数据(称为爬行)。这些程序通过跟踪其他页面的链接或查看站点地图来查找 Web 内容和功能。如果一个网站使用一个特殊的文件robots.txt来列出它不希望搜索引擎获取的页面,那么列出的页面将被忽略。这是一个基本概述 - Google 对搜索引擎的工作原理提供了更深入的解释。
测试人员可以使用搜索引擎对网站和 Web 应用程序执行侦察。搜索引擎发现和侦察有直接和间接的要素:直接方法涉及从缓存中搜索索引和相关内容,而间接方法涉及通过搜索论坛、新闻组和招标网站来学习敏感的设计和配置信息。
一旦搜索引擎机器人完成爬行,它就会开始根据标签和相关属性(例如 )对网页内容编制索引<TITLE>,以便返回相关的搜索结果。如果robots.txt文件在网站的生命周期内没有更新,并且没有使用指示机器人不索引内容的内联 HTML 元标记,那么索引可能包含网站不打算包含的内容拥有者。网站所有者可以使用前面提到robots.txt的 HTML 元标记、身份验证和搜索引擎提供的工具来删除此类内容。
测试目标
- 确定应用程序、系统或组织的哪些敏感设计和配置信息直接(在组织的网站上)或间接(通过第三方服务)公开。
如何测试
使用搜索引擎搜索可能敏感的信息。这可能包括:
- 网络图和配置;
- 管理员或其他主要员工的存档帖子和电子邮件;
- 登录程序和用户名格式;
- 用户名、密码和私钥;
- 第三方或云服务配置文件;
- 显示错误信息内容;和
- 非公共应用程序(开发、测试、用户验收测试 (UAT) 和站点的暂存版本)。
搜索引擎
不要将测试仅限于一个搜索引擎提供商,因为不同的搜索引擎可能会产生不同的结果。搜索引擎结果可能会在几个方面有所不同,具体取决于引擎上次抓取内容的时间,以及引擎用来确定相关页面的算法。考虑使用以下(按字母顺序列出的)搜索引擎:
- 百度,中国最受欢迎的搜索引擎。
- Bing是微软拥有和运营的搜索引擎,全球第二受欢迎。支持高级搜索关键字。
- binsearch.info,二进制 Usenet 新闻组的搜索引擎。
- Common Crawl,“任何人都可以访问和分析的网络爬虫数据的开放存储库。”
- DuckDuckGo是一个以隐私为中心的搜索引擎,可以从许多不同的来源编译结果。支持搜索语法。
- Google提供世界上最受欢迎的搜索引擎,并使用排名系统尝试返回最相关的结果。支持搜索运算符。
- Internet Archive Wayback Machine,“以数字形式构建互联网站点和其他文化制品的数字图书馆。”
- Shodan,一种用于搜索联网设备和服务的服务。使用选项包括有限的免费计划以及付费订阅计划。
搜索运算符
搜索运算符是一种特殊的关键字或语法,可扩展常规搜索查询的功能,并有助于获得更具体的结果。它们通常采用operator:query. 以下是一些通常支持的搜索运算符:
site:将搜索限制在提供的域中。inurl:将只返回在 URL 中包含关键字的结果。intitle:只会返回页面标题中包含关键字的结果。intext:或者inbody:只会在页面正文中搜索关键字。filetype:将仅匹配特定文件类型,即.png, 或.php.
例如,要查找由典型搜索引擎索引的 owasp.org 的 Web 内容,所需语法为:
site:owasp.org
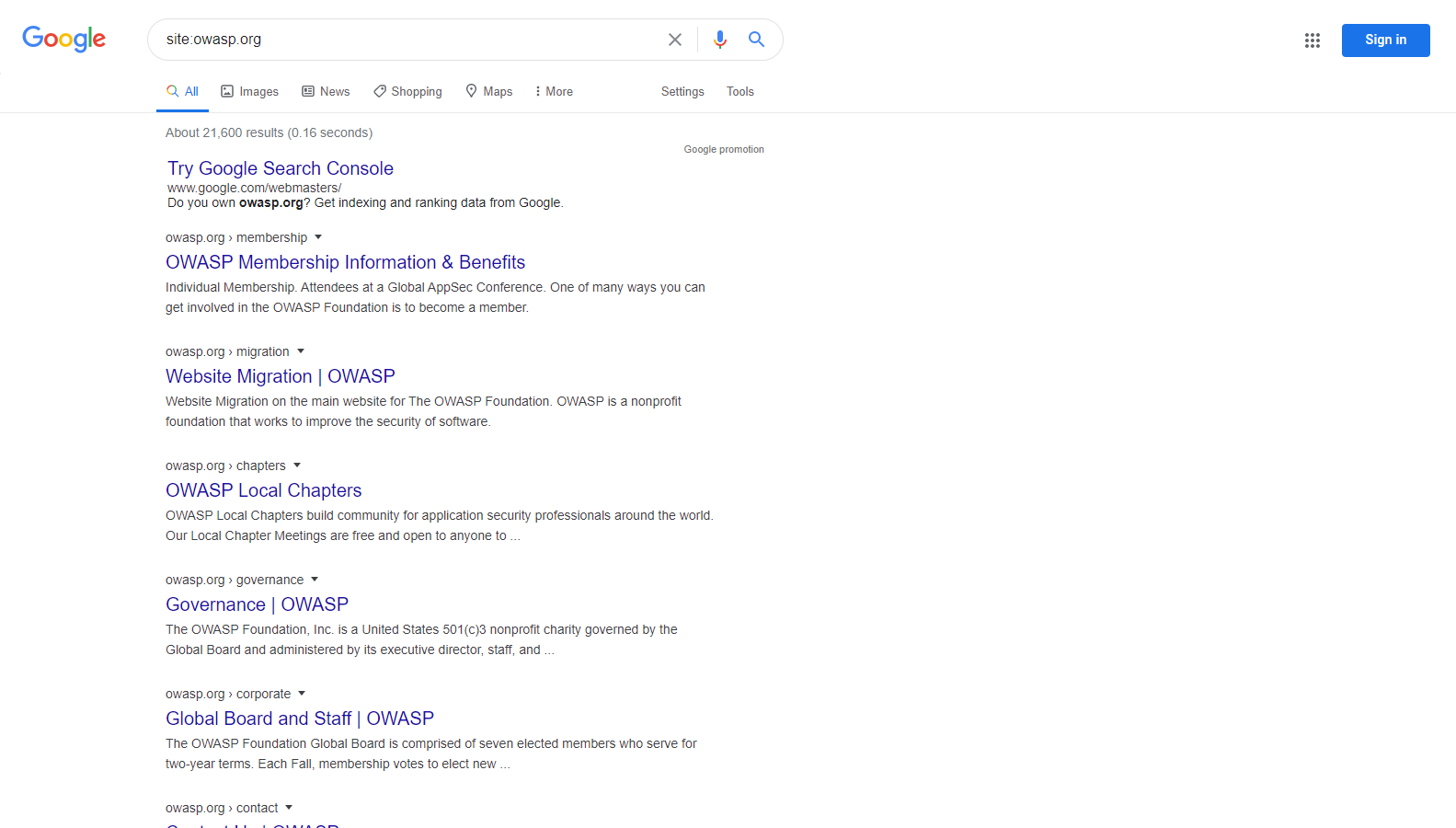
图 4.1.1-1:Google 站点操作搜索结果示例
查看缓存内容
要搜索以前已编入索引的内容,请使用cache:运算符。这有助于查看自索引以来可能已更改的内容,或者可能不再可用的内容。并非所有搜索引擎都提供缓存内容进行搜索;在撰写本文时最有用的来源是谷歌。
要owasp.org在缓存时查看,语法为:
cache:owasp.org
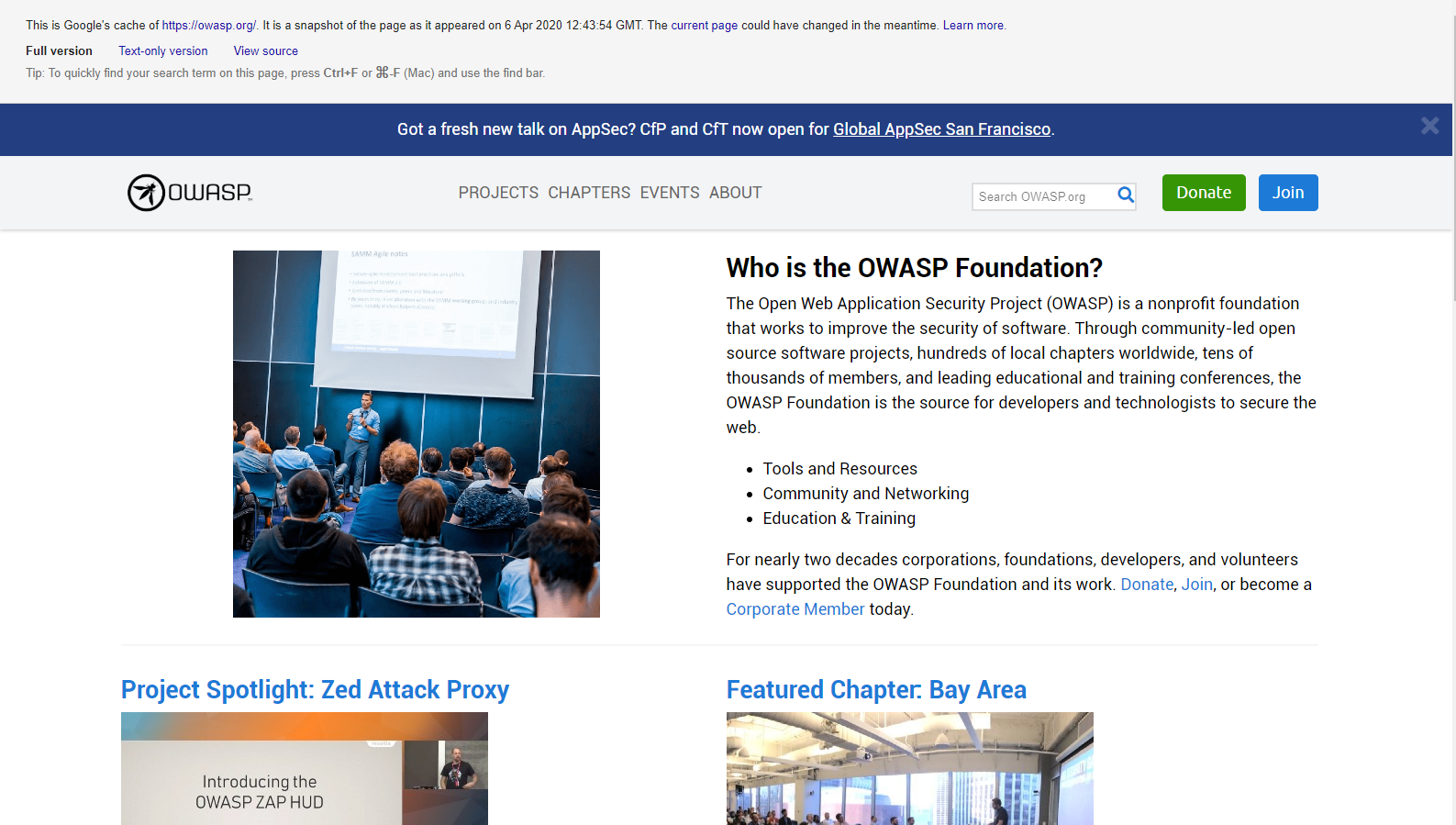
图 4.1.1-2:谷歌缓存操作搜索结果示例
谷歌黑客,或 Dorking
当与测试人员的创造力相结合时,使用运算符进行搜索可能是一种非常有效的发现技术。可以链接运算符以有效地发现特定种类的敏感文件和信息。这种称为Google hacking或 Dorking 的技术也可以使用其他搜索引擎,只要支持搜索运算符。
诸如Google Hacking Database之类的 dorks 数据库是一种有用的资源,可以帮助发现特定信息。该数据库中可用的一些类别的 dorks 包括:
- 立足点
- 包含用户名的文件
- 敏感目录
- Web 服务器检测
- 易受攻击的文件
- 易受攻击的服务器
- 错误信息
- 包含多汁信息的文件
- 包含密码的文件
- 敏感的在线购物信息
整治
在将设计和配置信息发布到网上之前,请仔细考虑其敏感性。
定期审查在线发布的现有设计和配置信息的敏感性。